import numpy as np
from sim_tools.distributions import Exponential, NormalRandomness
Learning objectives:
- Understand randomness and pseudorandom number generators.
- Explore tools for random sampling.
- Learn about independent random number streams.
Relevant reproducibility guidelines:
- STARS Reproducibility Recommendations: Control randomness.
Required packages:
These should be available from environment setup in the “Test yourself” section of Environments.
library(simEd)Randomness
When simulating real-world systems (e.g. patients arriving, prescriptions queueing), using fixed values is unrealistic. Instead, discrete-event simulations rely on randomness: they generate event times and outcomes by sampling randomly from probability distributions.
However, computers can’t generate “true” randomness. Instead, they use pseudorandom number generators (PRNGs): algorithms which produce a sequence of numbers that appear random, but are in fact completely determined by an initial starting point called a seed. If you use the same seed, you’ll get the same random sequence every time - a crucial feature for reproducibility in research and development.
By default, most software PRNGs initialise the seed based on something that changes rapidly, such as the current system time. This ensures a unique sequence with every fresh run. But for reproducible experiments, you should manually set the seed yourself, allowing you and others to exactly recreate simulation results.
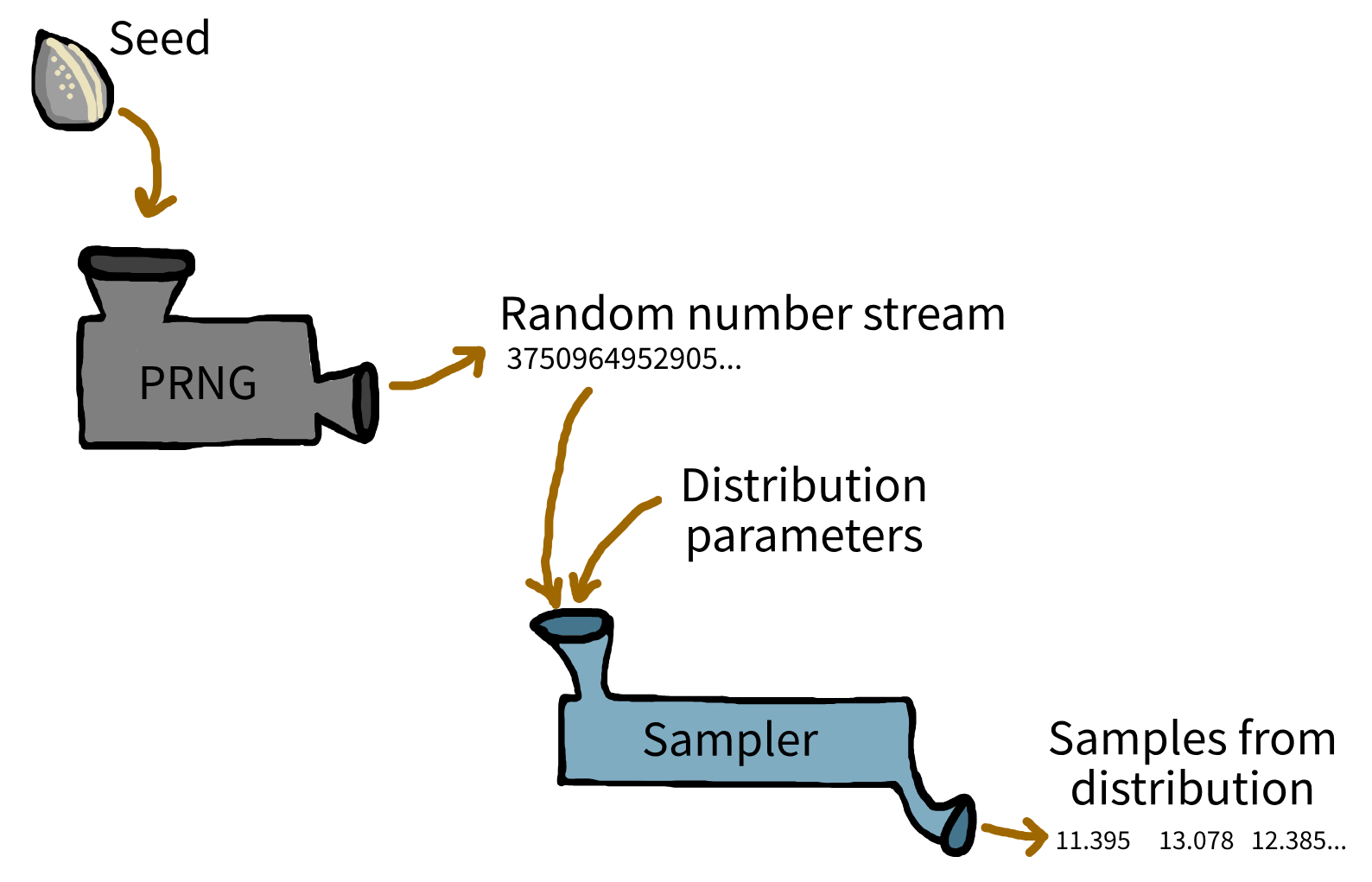
Introducing tools for random sampling
NumPy
NumPy is a widely used Python package for generating random numbers. Since NumPy version 1.17, the recommended approach for random sampling is through the new Generator API.
To start, create a generator object using np.random.default_rng(). This generator is an independent random number source and manages its own random state. It offers methods for generating random samples from many distributions, such as normal, exponential, and uniform.
For example, to generate 3 samples from an exponential distribution (with a mean of 17):
rng = np.random.default_rng()
rng.exponential(scale=17, size=3)array([17.89302372, 5.72899296, 21.52434864])To ensure the same results everytime the code runs, initialise with a fixed seed:
# Create a generator with a fixed seed for reproducibility
rng = np.random.default_rng(seed=20)
# Generate 3 samples from an exponential distribution (mean=17)
sample1 = rng.exponential(scale=17, size=3)
# Reset the generator with the same seed
rng = np.random.default_rng(seed=20)
# Generate 3 samples again (should be identical to the first run)
sample2 = rng.exponential(scale=17, size=3)
# Print the results
print(f"First run: {sample1}")First run: [3.64795914 9.04242889 2.27536902]print(f"Second run (same seed): {sample2}")Second run (same seed): [3.64795914 9.04242889 2.27536902]Legacy API (not recommended for new code)
You might encounter older code using NumPy’s legacy random number API. This approach sets a global seed and samples using functions like np.random.exponential():
np.random.seed(20)
np.random.exponential(scale=17, size=3)array([15.07984079, 38.75965673, 37.76190224])sim-tools
The sim-tools package (developed by Prof. Tom Monks) provides an object-oriented approach to sampling from a variety of statistical distributions.
sim-tools builds on NumPy’s random number generator and distributions. This means you get the same reliable, well-tested methods, with a convenient object-oriented interface. The package also includes some additional distribution types and tools for simulation.
To use sim-tools, you import the class for the distribution you need, specify parameters, and then use the instance to generate samples. Each object has its own seed and random state.
For example:
# Create an Exponential distribution object with mean 6 and seed 3
exp = Exponential(mean=6, random_seed=3)
# Generate 3 random samples
samples = exp.sample(size=3)
print(samples)[0.66008888 2.33794124 8.39724575]In R, random sampling is typically done with functions from the stats package. To ensure reproducibility, set a global random seed with set.seed(). Then use the appropriate function for your desired distribution.
For example, the exponential distribution is sampled with rexp() which requires the rate parameter (the inverse of the mean). To generate 3 samples from an exponential distribution with a mean of 6, you would use:
set.seed(3L)
rexp(n = 3L, rate = 1L / 6L)[1] 10.383759 3.690197 7.397500Independent random number streams
In your simulation, you often have multiple distinct processes that involve random sampling (e.g. patients arriving, consultation lengths, routing decisions).
If these processes share the same random number generator, changes in one part of your model (like altering the number of samples drawn for arrivals) can unintentionally affect the random numbers used elsewhere. This can introduce subtle, hard-to-detect errors, making your simulation harder to debug and compare across scenarios.
To demonstrate this problem, we will sample from two distributions: arrivals and processing times.
Solution: independent generators
rng_a = np.random.default_rng(1)
rng_p = np.random.default_rng(2)
arrivals = rng_a.exponential(scale=3, size=3)
processing = rng_p.normal(loc=10, scale=2, size=3)
print(f"Arrivals: {arrivals}\nProcessing: {processing}")Arrivals: [ 3.21908708 0.92535943 16.12631062]
Processing: [10.37810676 8.95450312 9.17387291]rng_a = np.random.default_rng(1)
rng_p = np.random.default_rng(2)
arrivals = rng_a.exponential(scale=3, size=5)
processing = rng_p.normal(loc=10, scale=2, size=3)
print(f"Arrivals: {arrivals}\nProcessing: {processing}")Arrivals: [ 3.21908708 0.92535943 16.12631062 1.09928134 0.34608612]
Processing: [10.37810676 8.95450312 9.17387291]✅ Processing samples remain the same.
sim-tools
The same rule applies for sim-tools: use one object per process, each with it’s own seed.
arrivals_exp = Exponential(mean=3, random_seed=1)
processing_norm = Normal(mean=10, sigma=2, random_seed=2)
arrivals = arrivals_exp.sample(3)
processing = processing_norm.sample(3)
print(f"Arrivals: {arrivals}\nProcessing: {processing}")Arrivals: [ 3.21908708 0.92535943 16.12631062]
Processing: [10.37810676 8.95450312 9.17387291]arrivals_exp = Exponential(mean=3, random_seed=1)
processing_norm = Normal(mean=10, sigma=2, random_seed=2)
arrivals = arrivals_exp.sample(5)
processing = processing_norm.sample(3)
print(f"Arrivals: {arrivals}\nProcessing: {processing}")Arrivals: [ 3.21908708 0.92535943 16.12631062 1.09928134 0.34608612]
Processing: [10.37810676 8.95450312 9.17387291]✅ Processing samples remain the same.
Which package did we use?
We’ve used sim-tools for sampling in the example models in this book. This is because, with sim-tools, you’re encouraged to use independent random number streams by design, as each distribution gets its own instance of a distribution class, each with its own parameters and random seed.
You can still use NumPy directly if you prefer - you’ll just need to remember to deliberately create separate random generators, as it’s not “enforced”. If you don’t explicitly create one per stream, it’s easy to accidentally fall back on using a single generator.
Problem: single random number stream
set.seed(1L)
arrivals <- rexp(n = 3L, rate = 1L / 3L)
processing <- rnorm(n = 3L, mean = 10L, sd = 2L)
print(arrivals)[1] 2.2655455 3.5449283 0.4371202print(processing)[1] 12.65960 12.54486 10.82928Change to five arrivals samples:
set.seed(1L)
arrivals <- rexp(n = 5L, rate = 1L / 3L)
processing <- rnorm(n = 3L, mean = 10L, sd = 2L)
print(arrivals)[1] 2.2655455 3.5449283 0.4371202 0.4193858 1.3082059print(processing)[1] 6.920100 8.142866 9.410559⚠️ Processing samples have changed, despite no changes to their sampling code!
This happens because both processes share a single random number generator: drawing more arrival samples moves the sequence forward, so the processing draws start from a different place. But in R, exactly how the random numbers are used depends not just on how many you draw, but which distributions you use and their internal algorithms.
Each call to a random function in R advances the internal generator, but different distributions might use up the stream at different rates. For example, generating one normal value might use more than one core random draw. So the link between arrival and processing samples - shown as A, B, C, etc. - only gives a rough idea, not an exact step-by-step mapping.
Sampling three arrivals:
| RNG state | Arrival sample | Processing sample |
|---|---|---|
| A | 2.2655455 | - |
| B | 3.5449283 | - |
| C | 0.4371202 | - |
| D | - | 12.65960 |
| E | - | 12.54486 |
| F | - | 10.82928 |
Sampling five arrivals:
Processing now uses states F, G, H instead of D, E, F.
| RNG state | Arrival sample | Processing sample |
|---|---|---|
| A | 2.2655455 | - |
| B | 3.5449283 | - |
| C | 0.4371202 | - |
| D | 0.4193858 | - |
| E | 1.3082059 | - |
| F | - | 6.920100 |
| G | - | 8.142866 |
| H | - | 9.410559 |
In R, changing how many samples you draw for one process will almost always change the random numbers used later - even more so when you mix different distributions. That’s why results can shift unexpectedly, even if you only changed the arrivals.
Solution: independent streams
By default, R’s stats package uses a single random number stream and does not support managing multiple, independent streams.
The simEd package, last updated in 2023, provides equivalent functions that allow separate random number streams. The package is described in:
B. Lawson and L. M. Leemis, “An R package for simulation education,” 2017 Winter Simulation Conference (WSC), Las Vegas, NV, USA, 2017, pp. 4175-4186, doi: 10.1109/WSC.2017.8248124 https://ieeexplore.ieee.org/document/8248124.
To use simEd, take the code from above but change the prefix on functions from r to v - so rexp becomes vexp, and rnorm becomes vnorm.
set.seed(1L)
arrivals <- vexp(n = 3L, rate = 1L / 3L)
processing <- vnorm(n = 3L, mean = 10L, sd = 2L)
print(arrivals)[1] 0.9257312 1.3962373 2.5518837print(processing)[1] 12.659599 8.328743 12.544859set.seed(1L)
arrivals <- vexp(n = 5L, rate = 1L / 3L)
processing <- vnorm(n = 3L, mean = 10L, sd = 2L)
print(arrivals)[1] 0.9257312 1.3962373 2.5518837 7.1646835 0.6757445print(processing)[1] 12.54486 13.19056 10.82928✅ Processing samples remain the same.
Note👥 Acknowledgements
This section on simEd is adapted from the R sampling page in Monks, Thomas, Alison Harper, Amy Heather, and Navonil Mustafee. 2024. “Towards Sharing Tools, Artifacts, and Reproducible Simulation: a ’simmer‘ model example.” Zenodo. https://doi.org/10.5281/zenodo.11222943 (MIT Licence).
We also acknowledge the work of B. Lawson and L. M. Leemis for the simEd package and their contributions to simulation education.
Which package did we use?
We’ve used R’s standard random sampling functions in the example models in this book. This is mainly because they’re fast, even though all draws share a single global random stream. If you need independent streams, the simEd package allows for that, but it can slow things down—which is why we didn’t use it here.
Is this a big deal?
These quirks with random number streams are worth understanding, especially for modellers concerned with detailed reproducibility, or if you find yourself debugging odd glitches in sensitivity analyses.
With Python, it’s easy to avoid pitfalls from shared random number streams - just use the new Generator API (np.random.default_rng) to create separate generators for each process in your simulation, rather than sharing a global one, or packages like sim-tools. That said, for most simulations, even if you use a single stream, the impact is usually minor - so it’s not something to stress over.
For most everyday simulation work though, this isn’t a disaster! In fact, for standard DES models in R (like our examples), it’s quite normal to rely on the default setup - where all random draws come from a single, global stream. Unless you’re doing really specialised work, like comparing many scenarios in fine detail, the impact on your results is typically minor.
The key is simply to be aware of how shared random number streams work, so you aren’t caught by surprise if results subtly shift when you tweak the simulation structure.
What’s next?
On the next page, we’ll learn how to add sampling to your model through the example of generating some patients arriving in your simulation.
Test yourself
NoteWhat is a pseudorandom number generator (PRNG)?
NoteWhat is the role of a seed in a PRNG?
NoteWhy is it recommended to use independent random number streams in simulation models?
NoteWhich of the following statements best describes the difference between NumPy’s legacy random API and the Generator API?
NoteIn the
sim-tools package, how do you ensure separate random number streams for different processes?
NoteWhat is the limitation of R’s base random number generation for simulation?
If you haven’t already, try out random sampling for yourself!
Have a go with NumPy and sim-tools.
Have a go with base R and simEd.
Sample random numbers from a distribution - try exponential, normal, or uniform.
Set and change the seed, then sample again. Do you get the same results each time?
Increase the number of samples for one process - see if results for other streams change.