Review sensitivity analysis from 50 million and set to run with 100 million. Total time used: 19h 6m (47.8%)
09.28-09.31, 09.37-09.44: Review results from 50 million
Realised mistake - had run sensitivity analysis with 50 million rather than intended 100 million.
Reflection
With high run times like this, a simple mistake means another day waiting for results. Probably worth reflecting on the run time of the code itself in the article, and how in cases like this, it means it spans days waiting for different runs.
Alas, will review results with 50 million, and set to run 100.
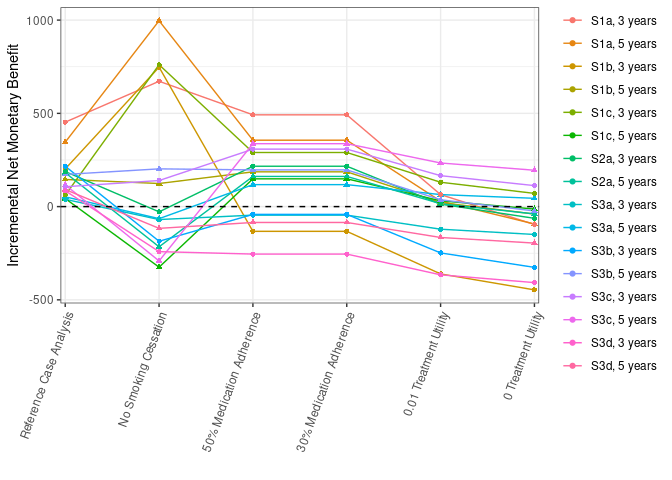
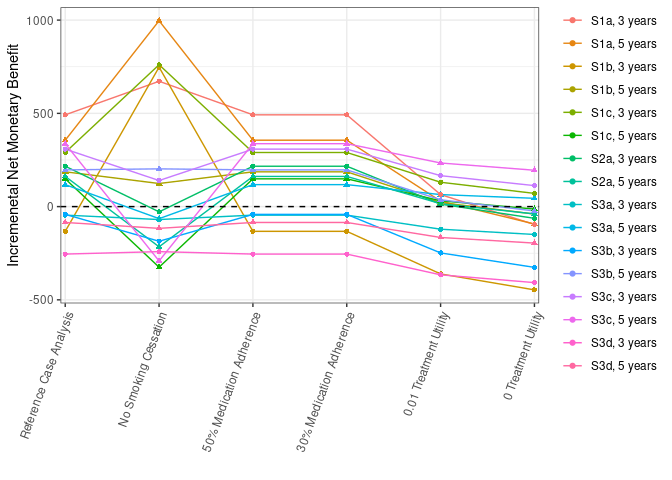
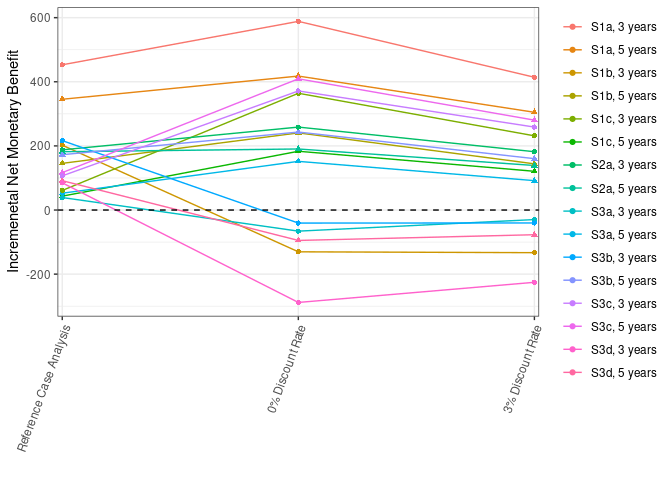
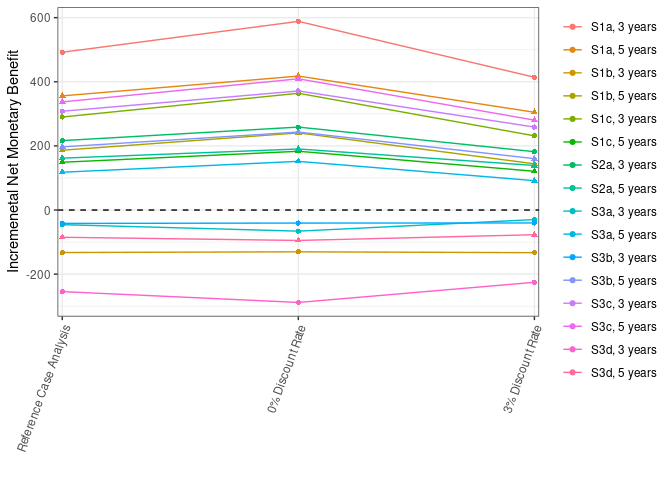
Ran Process_Sensitivity_Analysis.Rmd. Results all still quite far off.
From 50 million:
For reference, from 100 thousand:
From 50 million:
For reference, from 100 thousand:
Timings
import syssys.path.append('../')from timings import calculate_times# Minutes used prior to todayused_to_date =1136# Times from todaytimes = [ ('09.28', '09.31'), ('09.37', '09.44')]calculate_times(used_to_date, times)
Time spent today: 10m, or 0h 10m
Total used to date: 1146m, or 19h 6m
Time remaining: 1254m, or 20h 54m
Used 47.8% of 40 hours max