Fixed my loading of epicR so get model results! Experiemented with agent numbers and started Table 3. Total time used: 6h 11m (15.5%)
09.19-09.41: Returning to run the model
Did a quick review of my prior logbook entries to get back up to speed. Will be trying to run Mini_Analysis.Rmd, which I had created previously and contains only scenario S1NoCD and saves the result to csv (whilst the full script Case_Detection_Results.Rmd contains many more scenarios. I had previously reduced the number of agents (settings$n_base_agents <-) to try and run on my local machine but this just returned 0/1/NaN, so I will now be trying with the full number of agents.
In Case_Detection_Results.Rmd, it sets settings$n_base_agents <- 50e+6 but has comment “change number of agents here: 100e+6 is used in the analysis”.
I decided to start with trying Mini_Analysis.Rmd with 50e+6. I logged into the remote computer, cloned the GitHub repository, then ran the following:
cd stars-reproduce-johnson-2021/reproduction
Rscript -e "renv::restore()"
Rscript -e "rmarkdown::render('scripts/Mini_Analysis.Rmd')"
This however returned an error that pandoc was required, so I ran sudo apt install pandoc then tried again. This then successfully rendered the .Rmd. I initially did 5000 agents to make sure it worked and output correctly, and then the original 50e+6 as mentioned.
11.29-11.34, 11.48-12.00: Reviewing results from 50e+6
This ran in 1.642896 hours (1 hour 38 minutes). The result was still wrong though:
import pandas as pdpd.read_csv('mini_analysis_50e6.csv')
Scenario
Agents
PatientYears
CopdPYs
NCaseDetections
DiagnosedPYs
OverdiagnosedPYs
SABA
LAMA
LAMALABA
...
NoCOPD
GOLD1
GOLD2
GOLD3
GOLD4
Cost
CostpAgent
QALY
QALYpAgent
NMB
0
S1NoCD
0
0
0
0
0
0
NaN
NaN
NaN
...
0
0
0
0
0
0
NaN
0
NaN
NaN
1 rows × 29 columns
From the Case_Retection_Results.md in their repository, I can see that I should be getting numbers like 37195539 agents, 625946560 patient years, 71206641 CopdPYs, and so on.
I’m sceptical that increasing to 100e+6 would fix that issue, as their notebooks appear to have been run with 50e+6, as I did.
I double-checked the code in Mini_Analysis.md, but was satisfied that this matched up with theirs, with the only changes being to import epicR from the local folder, and to add a timer, and not having some processing of the table (but that would make no difference here, as numbers 0 and NaN).
I’m presuming the issue therefore is in the epicR package I have, but I’m rather unsure on where to start, or where the issue might be!
12.01-12.24: Basic run of epicR to resolve the “0” results issue
As I starting point, I tried following the instructions available for running epicR generally (and not this specific study), to see if I could get it working and printing some results for a random basic scenario.
However, I later realised this was a newer function in epicR and not in the version we have.
I loaded my local epicR package, although without warning=False, realised it had a warning:
Warning: ── Conflicts ───────────────────────────────────────────────────────────────────────────────── epicR conflicts
──
✖ `Cget_agent_events` masks `epicR::Cget_agent_events()`.
✖ `Cget_all_events` masks `epicR::Cget_all_events()`.
✖ `Cget_all_events_matrix` masks `epicR::Cget_all_events_matrix()`.
… and more.
ℹ Did you accidentally source a file rather than using `load_all()`?
Run `rm(list = c("Cget_agent_events", "Cget_all_events", "Cget_all_events_matrix", "Cget_event",
"Cget_events_by_type", "Cget_inputs", "Cget_n_events", "Cget_output", "Cget_output_ex", "Cget_runtime_stats",
"Cget_settings", "Cget_smith", "Cset_input_var", "Cset_settings_var", "get_sample_output", "mvrnormArma"))` to
remove the conflicts.
I found that, if I ran the whole script just with the local devtools::load_all("../epicR"), it would appear to run but give results like 0. If however I cleared the environment and then ran library(epicR) below the load_all() statement, it would run and give actual results. I’m presuming this relates to the conflicts message above. I understand that, when I clear the environment, I’m removing objects, states and data that might have come with load_all() but keeping the package itself, so I am just left with a “clean slate” with the package.
12.25-12.30, 14.08-14.53, 15.10-15.14, 15.20-15.25: Fixing my mini analysis and returning to lower numbers of agents
I removed the Basic_Model.Rmd and returned to Mini_Analysis.Rmd, adding the new workflow of clearing the environment and reloading the library. I returned to running it with fewer numbers of agents. This output results - hurrah!
As I’d tried before, ran these (either on local machine or more high powered remote machine):
1 million (1e6) (4.7 minutes local, 2.0 minutes remote)
5 million (5e6) (27.3 minutes local, 10.0 minutes remote)
And it was quicker than before too! (17s vs 2.4m, 2.6m vs 18.2m).
import pandas as pd# Import resultsdf5e3 = pd.read_csv('mini_analysis_fixed_5e3.csv').rename(index={0: '5e3'})df5e4 = pd.read_csv('mini_analysis_fixed_5e4.csv').rename(index={0: '5e4'})df5e5 = pd.read_csv('mini_analysis_fixed_5e5.csv').rename(index={0: '5e5'})df1e6 = pd.read_csv('mini_analysis_fixed_1e6.csv').rename(index={0: '1e6'})df5e6 = pd.read_csv('mini_analysis_fixed_5e6.csv').rename(index={0: '5e6'})# Combine into a single dataframe and showdf_s1nocd = pd.concat([df5e3, df5e4, df5e5, df1e6, df5e6])df_s1nocd
Scenario
Agents
PatientYears
CopdPYs
NCaseDetections
DiagnosedPYs
OverdiagnosedPYs
SABA
LAMA
LAMALABA
...
NoCOPD
GOLD1
GOLD2
GOLD3
GOLD4
Cost
CostpAgent
QALY
QALYpAgent
NMB
5e3
S1NoCD
3696
6.233997e+04
7.457940e+03
18933
1.396640e+03
1387
0.017348
0.118369
0.148212
...
52174
3045
3113
749
178
8.072027e+06
2183.990032
4.642803e+04
12.561696
625900.832686
5e4
S1NoCD
37129
6.235741e+05
7.094660e+04
190251
1.322909e+04
13394
0.017161
0.134433
0.152504
...
525258
29237
30306
6618
1303
7.887546e+07
2124.362691
4.649150e+05
12.521615
623956.370519
5e5
S1NoCD
371579
6.251100e+06
7.066933e+05
1907271
1.310409e+05
133904
0.017192
0.136018
0.151516
...
5270314
287267
304912
67938
12088
7.985673e+08
2149.118458
4.660359e+06
12.542042
624952.967972
1e6
S1NoCD
743128
1.249876e+07
1.421786e+06
3814132
2.622621e+05
267345
0.017119
0.135762
0.151370
...
10529668
577647
613813
136603
24218
1.600396e+09
2153.593806
9.317379e+06
12.538055
624749.138617
5e6
S1NoCD
3718120
6.256653e+07
7.114655e+06
19087564
1.318087e+06
1336660
0.017180
0.135601
0.151460
...
52712576
2886521
3074656
685563
119768
7.978907e+09
2145.951883
4.663988e+07
12.543942
625051.169501
5 rows × 29 columns
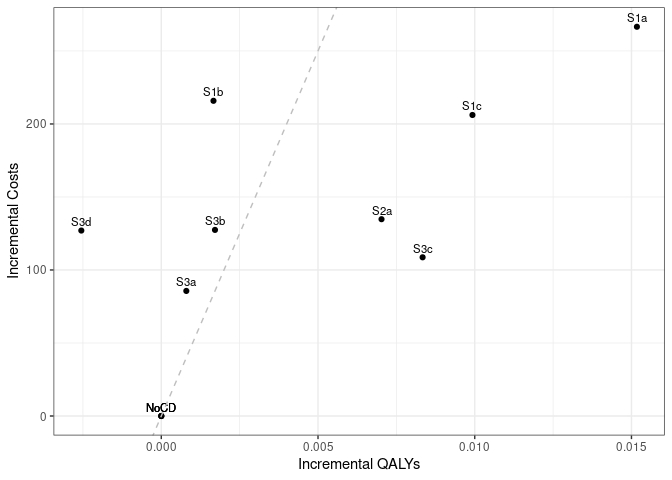
Can’t calculate ICER as need incremental costs and qalys, and those need S1a, S1b and S1c to make incrementalcosts, incrementalqaly and incrementalnmb, since they compare against S1NoCD.
Comparing against S1NoCD from Case_Detection_Results.md:
Some columns are different as their numbers depend on number of agents:
Agents
PatientYears
CopdPYs
NCaseDetections
DiagnosedPYs
OverdiagnosedPYs
Mild, Moderate, Severe, VerySevere
NoCOPD
GOLD1, GOLD2, GOLD3, GOLD4
Cost
QALY
But some are clearly processed and so should look at these to see if same results:
SABA
LAMA
LAMALABA
ICSLAMALABA
MildPY, ModeratePY, SeverePY, VerySeverePY
CostpAgent
QALYpAgent
NMB
I filtered to those columns, and add the results from Case_Detection_Results.md…
# Filter to columns not influenced by agent numbers1 = df_s1nocd[['SABA', 'LAMA', 'LAMALABA', 'ICSLAMALABA', 'MildPY','ModeratePY', 'SeverePY','VerySeverePY', 'CostpAgent', 'QALYpAgent', 'NMB']]# Add original results to dataframeoriginal = {'SABA': 0.017,'LAMA': 0.135,'LAMALABA': 0.151,'ICSLAMALABA': 0.080,'MildPY': 0.217,'ModeratePY': 0.041,'SeverePY': 0.068,'VerySeverePY': 0.006,'CostpAgent': 2150.057,'QALYpAgent': 12.544,'NMB': 625073.2}original_row = pd.DataFrame(original, index=['original'])s1 = pd.concat([s1, original_row])# View dataframe, rounding to 3dp (as they present it in original)round(s1, 3)
SABA
LAMA
LAMALABA
ICSLAMALABA
MildPY
ModeratePY
SeverePY
VerySeverePY
CostpAgent
QALYpAgent
NMB
5e3
0.017
0.118
0.148
0.076
0.233
0.035
0.062
0.006
2183.990
12.562
625900.833
5e4
0.017
0.134
0.153
0.081
0.212
0.039
0.067
0.006
2124.363
12.522
623956.371
5e5
0.017
0.136
0.152
0.081
0.215
0.041
0.069
0.006
2149.118
12.542
624952.968
1e6
0.017
0.136
0.151
0.080
0.216
0.041
0.068
0.006
2153.594
12.538
624749.139
5e6
0.017
0.136
0.151
0.080
0.217
0.041
0.068
0.006
2145.952
12.544
625051.170
original
0.017
0.135
0.151
0.080
0.217
0.041
0.068
0.006
2150.057
12.544
625073.200
We can see that many columns look very similar between them. However, for MildPY, CostpAgent, QALYpAgent and NMB, the result 5e5 is markedly better than 5e4.
I then add 1 million (1e6) and 5 million (5e6) (already done above). And this looked pretty similar to 500,000 (5e5).
Looking at Case_Detection_Results.Rmd, there are 12 scenarios, and then another 12 for 5 years, so a total of 24.
I figured I could try running the whole thing with 500,000 to begin with, but up it to 1 million or 5 million if needed, but that 50 million probably wasn’t necessary (as anticipate will likely be able to get similar enough results with lower numbers).
15.26-15.38, 15.58-16.08, 16.18-16.53: Running the full original script
I re-copied the original script and only made the following amendments before running:
Altering import of epicR
Adding a timer
Reducing agent number from 50e6 (50 million) to 5e5 (500 thousand)
Saving results tables to csv files
Then ran on remote machine. It took a bit of tweaking to correct the saving into outputs folder and get right paths, as I got the path wrong, and then it wouldn’t work before had made “outputs” folder.
Finishing this, I got five results tables (saved to csv).
I initially focused on sall, and reworking it to be more similar to Table 3. Whilst doing this, I assumed that S1NoCD was S0, as the values were closest and as it was the first (as opposed to S2NoCD or S3NoCD).
Timings
import syssys.path.append('../')from timings import calculate_times# Minutes used prior to todayused_to_date =193# Times from todaytimes = [ ('09.19', '09.41'), ('11.29', '11.34'), ('11.48', '12.00'), ('12.01', '12.24'), ('12.25', '12.30'), ('14.08', '14.53'), ('15.10', '15.14'), ('15.20', '15.25'), ('15.26', '15.38'), ('15.58', '16.08'), ('16.18', '16.53')]calculate_times(used_to_date, times)
Time spent today: 178m, or 2h 58m
Total used to date: 371m, or 6h 11m
Time remaining: 2029m, or 33h 49m
Used 15.5% of 40 hours max