Ran remaining experiments and created figures and tables, although unfortunately not reproduced and no further troubleshooting ideas. Total time used: 17h 41m (44.2%)
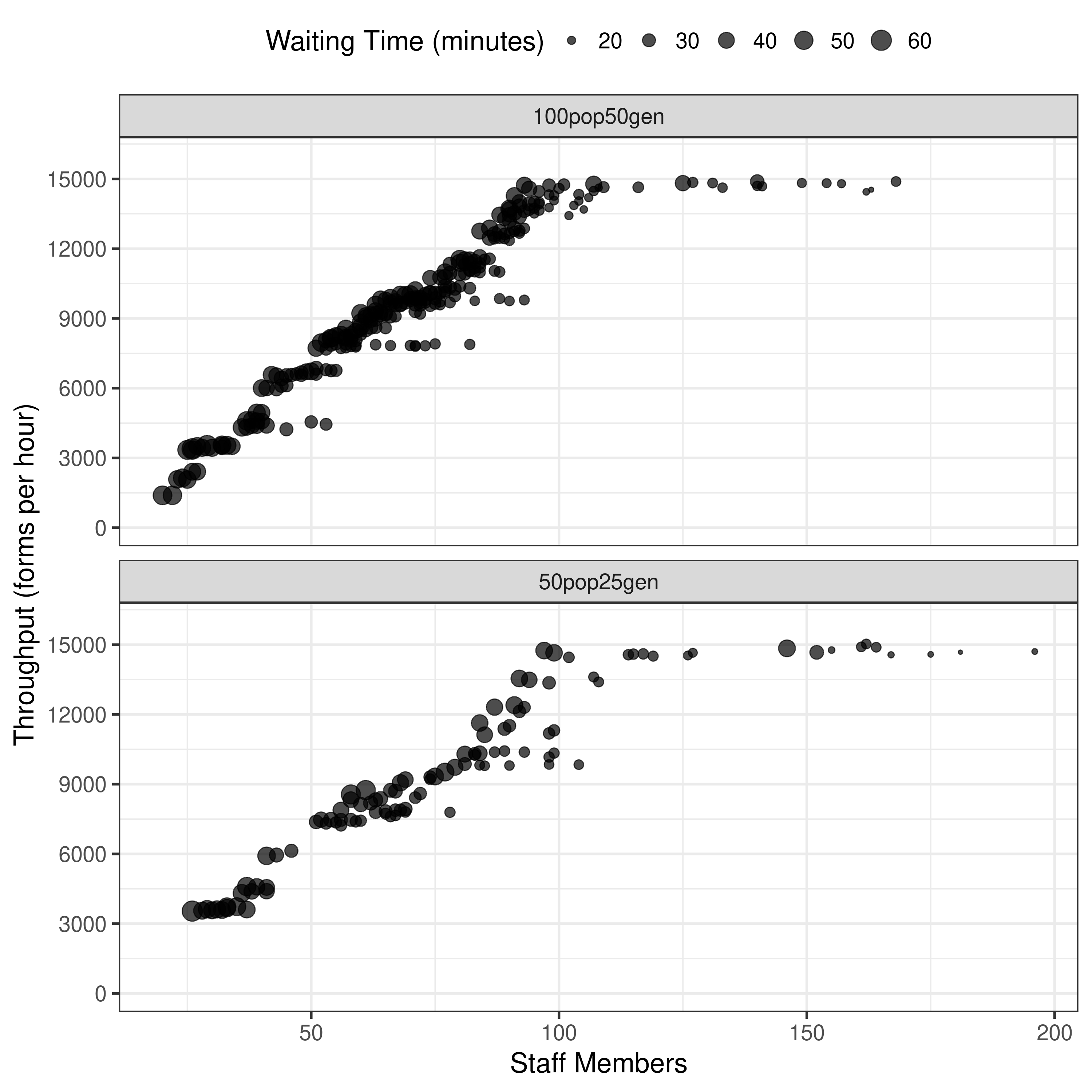
09.20-09.35: Running and processing Experiment 3
Was going to alter Experiment 3 to just do the two shorter scenarios, but then realised those had finished on Friday, and the process had only remained running for the longer scenario. However, the timings were missing, as that would have been done once all completed. Hence, still amended the script to just run two, and then set these to run, as I need to know the times.
I checked the results, and - unsurprisingly, given previous - these are similar but differ from the article.
Once this finished, it had a run time of: 3 hours 13 minutes
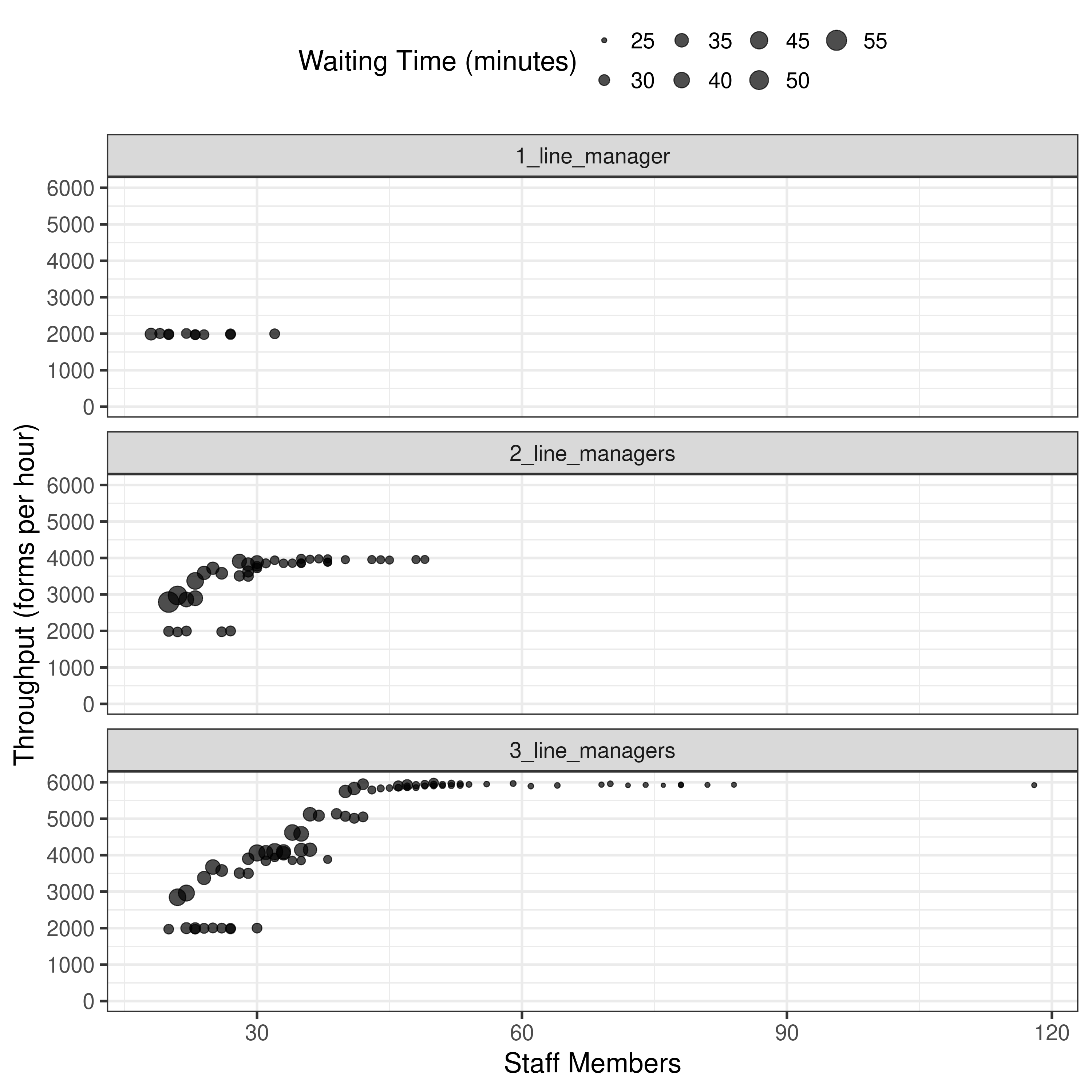
09.36-09.41, 09.50-10.07: Experiment 4
Experiment 4 is the tri-objective with a maximum of 1, 2 or 3 line managers (known as greeters in the code) ran with population 50 and 25 generations. We set the upper bounds for the number of line managers in StaffAllocationProblem.py:
To do so programmatically, I’ll need to make this an input to the class StaffAllocationProblem(), and then likewise in ExperimentRunner() and main.py where it is called, alike how I did for objectiveTypes.
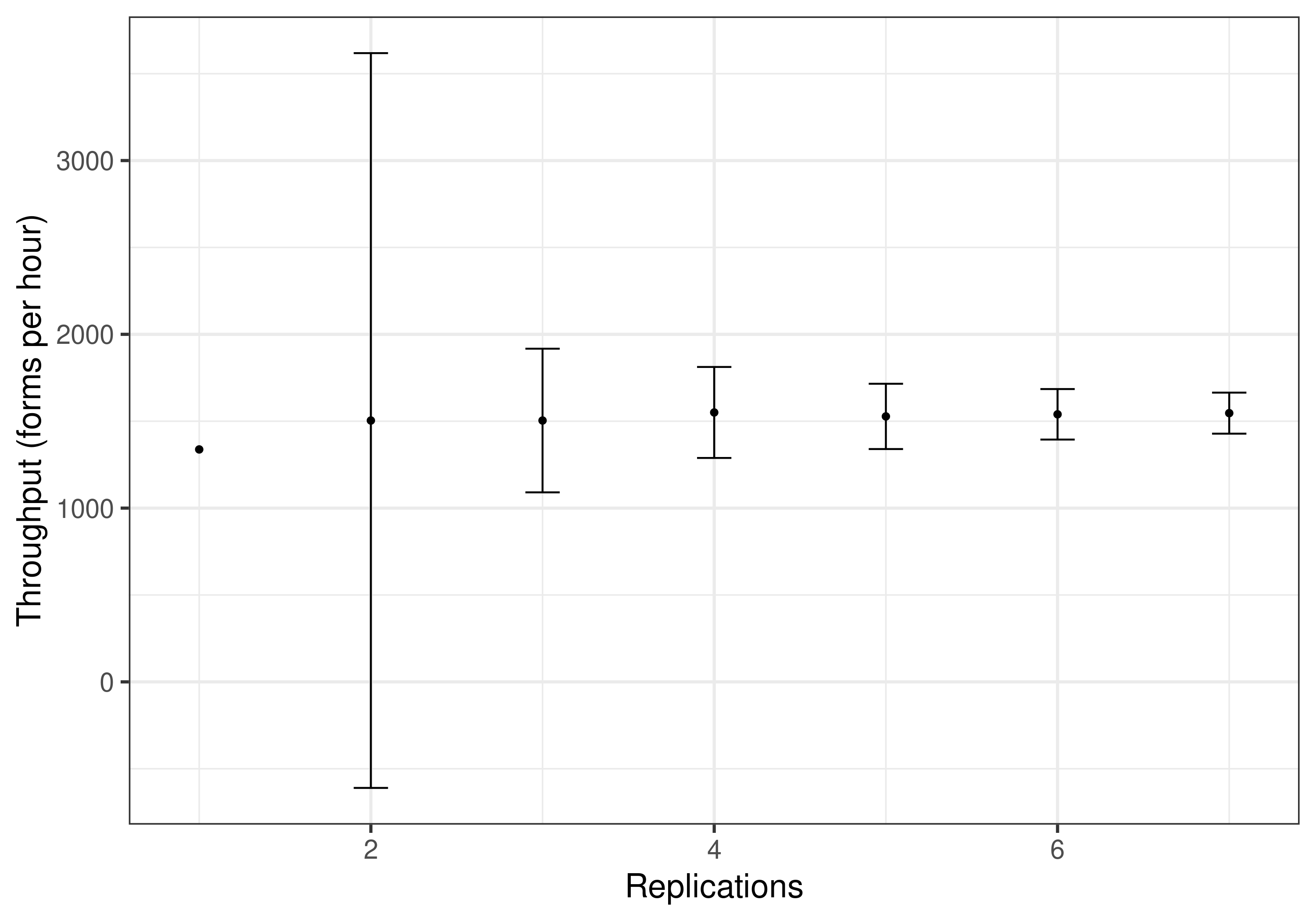
10.09-10.14, 10.18-10.28: Experiment 5
Experiment 5 has 6 dispensing, 6 sceening, 4 line manager and one medical. It then varies the number of replications from 1-7.
To set staff numbers, I’m assuming I’ll need to set upperBounds and lowerBounds to the same values, and so modified the code accordingly to allow input of lowerBounds.
To set number of replications, I’m assuming this is referring to runs, as that is an input that was set up, and I have previously assumed that when it says to set to run three times, it is referring to that parameter.
It doesn’t state population and generations, but I’m assuming generations is 1 (as it’s a fixed number of staff), and that population is 1000.
10.51-10.57: Processing Experiment 4
Run time: 37 minutes
As observed for similar figures previously, although patterns are similar, the axis values differ sufficiently that this is not reproduced (e.g. 10-120 staff members instead of 10-70, and 2000-6000 throughput rather than 500-5000 throughput).
However, the result from each was identical. I’m wondering if I changed the right thing? Looking at PODSimulation.py they have option of amending capacities:
########################
name = 'greeter'
n = 0
self.resources[name] = simpy.Resource(capacity=capacities[n],
name=name,
monitored=True)
self.monitors[name] = simpy.Monitor(name=name, ylab=ylab)
########################
name = 'screener'
n = 1
self.resources[name] = simpy.Resource(capacity=capacities[n],
name=name,
monitored=True)
self.monitors[name] = simpy.Monitor(name=name, ylab=ylab)
########################
name = 'dispenser'
n = 2
self.resources[name] = simpy.Resource(capacity=capacities[n],
name=name,
monitored=True)
self.monitors[name] = simpy.Monitor(name=name, ylab=ylab)
########################
name = 'medic'
n = 3
self.resources[name] = simpy.Resource(capacity=capacities[n],
name=name,
monitored=True)
self.monitors[name] = simpy.Monitor(name=name, ylab=ylab)
This seems to imply there are 0 greeters, 1 screener, 2 dispensers and 3 medics.
I’m wondering if perhaps I shouldn’t be running this like I have done so far, which is by searching through candidate solutions, given that this should only be the result of running the discrete event simulation? I completely changed Experiment5.py to run PODSimulation() directly. I borrowed code from StaffAllocationProblem.py.
Running this manually, I found I could get the same result (459.333333 throughoutput, 64.820665 time).
Then, in PODSimulation.py, I stumbled across the code that looks like it was designed to run this experiment:
I copied this into Experiment5.py, adapting it so that it saved the individual results to a file (rather than printing average results), and so it saved the time to a file too. To get individual results took a bit of work to figure out.
From StaffAllocationProblem.py, we know throughput = simulatorRunner.get_processed_count().
Hence, to get the throughput per simulation, we just need simul.get_number_out(). I saved this to .txt.
Run time: 8 seconds
I checked plotting_staff_results.r but it didn’t seem to have any code for this figure, so I wrote some to produce the figure.
And, alike I have found for other figures, I see a similar pattern in the results, although different values on the axises.
13.21-13.51, 13.58-14.27: Appendix A.1 (Table 3)
Appendix A.1 shows mean and confidence intervals for several different metrics. It is run with:
10% pre-screened
4 line manager
6 dispensing
6 screening
1 medical
Each with twenty replications. Hence, it appears this just directly uses the segment of code I had previously identified in PODSimulation.py and adapted for Experiment 5. These return average and half-width (which, as from this source, understand that the distance from mean to edge of confidence interval can be called the precision, margin of error or half-width).
It appears to have all the metrics needed, so all I needed to do was convert it into a table. From def __str__ I could see what components were used to make the printed output, and so what I needed for the table.
Add pandas to environment so could output a dataframe, although had to find one that was compatible with numpy 1.8.0, which meant using pandas from pip as condas doesn’t go back that far. It took a long time to install the pip dependencies, and then had module errors of ImportError: No module named dateutil.tz, though unresolved with install of python-dateutil, and so I decided to just output to csv and process in R.
However, I then started getting an error when importing myutils: ImportError: matplotlib requires dateutil. I think this probably resulted from my adding python-dateutil and then just pruning environment, so I deleted it and rebuilt it.
Run time: 10 seconds
Again however, this differed from the original.
import pandas as pdpd.read_csv('table3.csv')
Estimate
Avg
LowerBound
UpperBound
0
Wait time
66.66
63.75
69.57
1
No. in (Designees)
11979.15
11935.90
12022.40
2
No. out (Designees)
473.20
458.87
487.53
3
Dispensing wait time
18.84
18.33
19.35
4
Line mngr. wait time
23.73
23.60
23.86
5
Med. eval. wait time
9.06
6.05
12.06
6
Screening wait time
15.04
14.79
15.29
7
Dispensing no. waiting
434.81
423.35
446.27
8
Line mngr. no. waiting
4733.55
4705.73
4761.38
9
Med. eval. no. waiting
2.19
1.42
2.96
10
Screening no. waiting
569.06
560.52
577.61
14.29-14.38: Appendix A.2 (Table 4)
Table 4 is described as being results with line manager and 10% pre-screened. Hence, I’m assuming it’s just the pre-screen 10 results from Experiment 1?
These have 255 rows though, so I’m then assuming it’s just the first 40 rows.
It doesn’t appear reproduced, with quite different results, which was as I expected, given prior results.
res = pd.read_csv('exp1_prescreen10.txt', sep='\t')print(res.shape)res.head(40)
(255, 7)
greeter
screener
dispenser
medic
resources
throughput
time
0
4
1
14
1
20
435.000000
52.355130
1
4
1
14
3
22
435.666667
51.441467
2
7
1
14
1
23
650.000000
46.791091
3
8
1
14
1
24
669.666667
48.432571
4
7
1
14
3
25
647.000000
46.533784
5
4
6
14
1
25
1046.000000
53.590160
6
9
1
14
2
26
752.333333
43.787625
7
4
6
14
2
26
1048.333333
46.674927
8
5
6
14
1
26
1058.333333
61.717741
9
9
1
14
3
27
753.666667
43.688801
10
4
6
14
3
27
1096.666667
45.042496
11
4
6
14
4
28
1073.666667
44.577338
12
8
6
14
1
29
1103.000000
60.900434
13
4
6
14
6
30
1073.333333
44.503737
14
16
1
14
1
32
1079.666667
35.059892
15
4
10
14
4
32
1103.333333
43.141365
16
8
6
14
4
32
1111.666667
48.838884
17
8
6
14
5
33
1107.666667
48.787158
18
4
10
14
6
34
1094.000000
42.299897
19
4
6
25
1
36
1347.666667
46.158593
20
4
6
25
2
37
1351.666667
41.018076
21
5
6
25
1
37
1436.666667
50.700946
22
4
6
25
3
38
1371.666667
38.838681
23
5
6
25
2
38
1449.000000
42.375245
24
4
6
25
4
39
1371.000000
38.189643
25
5
6
25
3
39
1432.666667
42.123040
26
7
6
25
1
39
1546.666667
45.183401
27
5
6
25
4
40
1433.000000
39.702079
28
7
6
25
2
40
1545.333333
42.707594
29
4
10
25
1
40
1876.000000
43.735103
30
4
6
25
6
41
1373.666667
38.180682
31
4
10
25
2
41
1877.666667
38.542261
32
4
10
27
1
42
2055.000000
43.479165
33
4
10
25
4
43
1862.000000
31.677448
34
4
10
27
2
43
2045.666667
37.892850
35
4
10
25
5
44
1909.000000
31.112816
36
4
10
27
3
44
2006.333333
35.759831
37
18
1
25
1
45
1322.333333
30.449133
38
4
10
25
6
45
1915.333333
31.019967
39
4
10
27
4
45
2045.333333
32.732751
14.49-14.57: Final look over
I looked over the code again, trying to spot anything I could alter to help resolve discrepancy, but had no further ideas. I doubled checked the capacities in PODSimulation.py but was satisified these were coming from the provided inputs.
With no further ideas, I will stop at this point, and get (a) consensus from another team member on reproduction success, and (b) message the author to inform them and ask for suggestions if wish (although being quite aware that this was a very long time ago for them, so shouldn’t imagine that would be appropriate in this case).