Then ran main.py, but error when importing ExperimentRunner.py for import myutils: ImportError: No module named myutils. Tried tweaking the imports with no luck, so went with a simple solution of keeping myutils.py alongside the other scripts, rather than in reproduction/myutils/myutils.py.
Then realised it was because I was running from the parent folder, so switched that and it resolved the issue
matplotlib and networkx
Then found was missing matplotlib and networkx. Alike yesterday, choosing versions on or prior to 10 December 2013…
The file main.py is now able to run, and prints that programme has started and Experiment Runner 1.
We can see that main.py is looping through the files in experiments-to-run (which I later renamed inputs).
For each, it runs:
ParameterReader
ExperimentRunner
SolutionWriter
From the article, I anticipate that this could take a long time to run, and I’d ideally try to make sure I can run a “mini” version successfully first, before then exploring whether I need more computational power to run in full. To do this, I made test_run.ipynb, which requried adding ipykernel to the environment. However, this would not work, stating it needed updated versions, so it appears this is not supported for Python 2.7.
Unsupported versions and IDEs
Impact of IDEs - with VSCode being an issue in running 2.7. From a google, I can see likewise that Jupyter Notebook and JupterLab no longer support Python 2.7 (since 2020).
Running a mini version
In a case like this, if I were reusing the code for a new purpose, I might look to upgrade to Python 3+. However, for the sake of the reproduction, for now, sticking with 2.7. However, that brings limitations, like being unable to run notebooks, and having to use a pre-release version of the Python extension in VSCode to run the .py files.
Hence, I just made a test_run.py without the loop. I had a brief look into the documentation for the evolutionary algorithms with inspyred, looking at the parameters being input and whether I could lower these so I can do a temporary run.
runs=1 - already minimal
population=100 - used for popSize, so might also help if lower? This presentation mentions popsize 10 being faster than 100 or 500.
generations=5 - used for max_generations, so might help to lower to 1, just for test-run?
Reducing population to 10 and generations to 1 it ran in 42 seconds on my machine. This created a folder in reproduction/ with the current date and time. It contained the experiment txt file, and six results txt files.
Comparing to paper
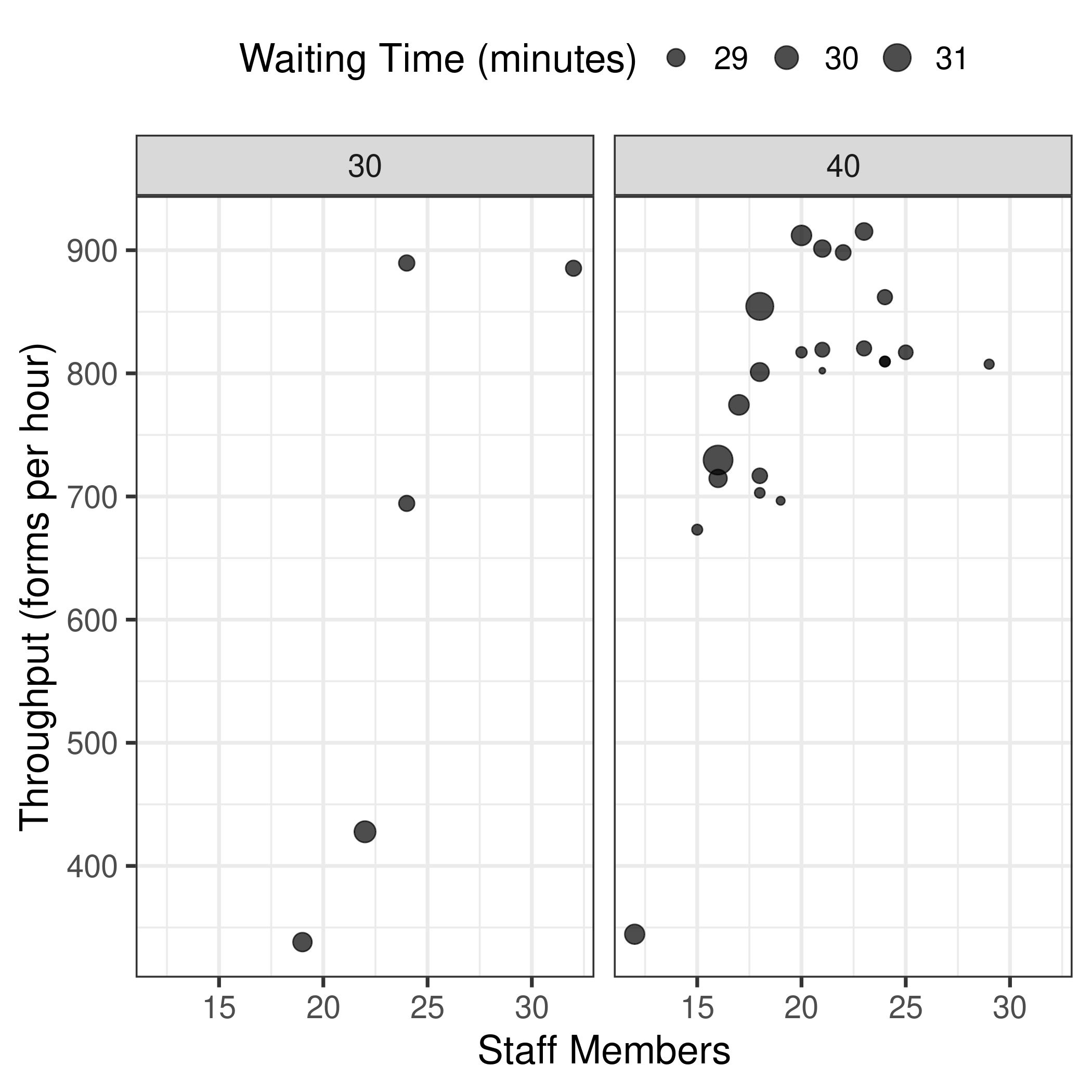
The nine files in experiments-to-run align with Figure 5, which has nine grids where percentage of pre-screened is 10 to 90%. These were run with a population of 100 and 50 generations. It has a stated computational time of 6.5 hours. Hence, I will need to adjust the parameters in main.py in order to run with 50 generations (and not 5).
The plots include staff members, throughput and waiting times. This lines up with the results.txt files, which contain columns for four different staff members, and then columns with throughput and time.
Run with population 100 and 5 generations
Running one of the scenarios (30% pre-screened) with parameters as in the code by default (100 and 5) took 22 minutes on my machine. This produced 23 results sheets (as summarised then in results.txt)
11.48-11.56: Setting up R
Analysis of the results was performed in R, and there is one R file provided: plotting_staff_results.r. This looks to have some of the code required, but not all (for example, no imports/pre-processing of txt files).
I set up an R project and an renv. In Figure 3 in the paper they state that R 2.15.3 with ggplot 0.9.3 was used. However, due to difficulties I’ve had with backdating R previously, I decided to try with latest versions in the first instance.
However, it was saying that it was up-to-date, so I tried instead:
renv::snapshot(packages="ggplot2")
This then add ggplot2 and its dependencies to the lockfile (not sure why the error had occurred).
11.58-12.25: Organising repository
Reorganised repository into python modelling scripts, R analysis scripts, and results, as it was quite busy.
I also removed some folders that contained results that were generated by the original author.
Altered SolutionWriter.py so that the:
Save path for the text files is to the new folder.
The save path can be altered from date/time to a custom path (so can save as e.g. experiment1/)
13.24-13.48: Test run of provided R code on dummy data
Set test_run.py to run with the parameters as in the paper (but by 5pm it was still running and I had to end it).
Installed R markdown dependencies into renv. However, had to run renv::snapshot(packages=c("ggplot2", "rmarkdown")) else it tried to drop things from the lockfile. I ran renv::settings$snapshot.type("all") and that resolved the issue.
I made some dummy data to run through the functions in plotting_staff_results.r. They include melt(), which seems likely to be from reshape/reshape2 so I add that to the environment, although these functions didn’t seem to work as provided, as there was something not right in melt().
For now, focussed on finding closest to Figure 5, which looks to be “#staff vs throughopu, faceting by prescreened”. This gives a good starting point.
13.55-14.09: Writing code to import txt data, combine and test plot
Imported the txt file data (which was already structured in a table in the format required) - just had to bind the tables together into one, and then use the plotting function. Adapted it slightly (e.g. alpha, layout of code) but otherwise very similar to as provided.
Now just a matter of doing it with some data from the real thing! From a full run.
Test run Figure 5
Timings
import syssys.path.append('../')from timings import calculate_times# Minutes used prior to todayused_to_date =138# Times from todaytimes = [ ('09.26', '09.55'), ('09.56', '10.06'), ('10.32', '11.03'), ('11.11', '11.27'), ('11.48', '11.56'), ('11.58', '12.25'), ('13.24', '13.48'), ('13.55', '14.09')]calculate_times(used_to_date, times)
Time spent today: 159m, or 2h 39m
Total used to date: 297m, or 4h 57m
Time remaining: 2103m, or 35h 3m
Used 12.4% of 40 hours max