Building a Reproducible Analytical Pipeline (RAP) for Simulation with Python and R
Building a Reproducible Analytical Pipeline (RAP) for Simulation with Python and R
Amy Heather
Postdoctoral Research Associate at the University of Exeter
NHS-OA Webinar 18th June 2026
![]()
![]()
![]()
Reproducibility
Reproducibility is the ability to regenerate results (e.g. tables, figures) using the provided code and data.
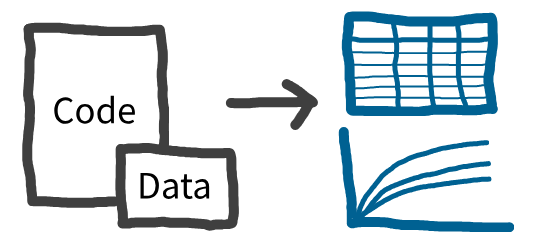
Reproducibility
Reproducibility is the ability to regenerate results (e.g. tables, figures) using the provided code and data.
Why?
- Reuse your own work more easily.
- Improve code clarity and quality
- Save time when revisiting analyses.
- Build trust.
- Help others verify and reuse your work.
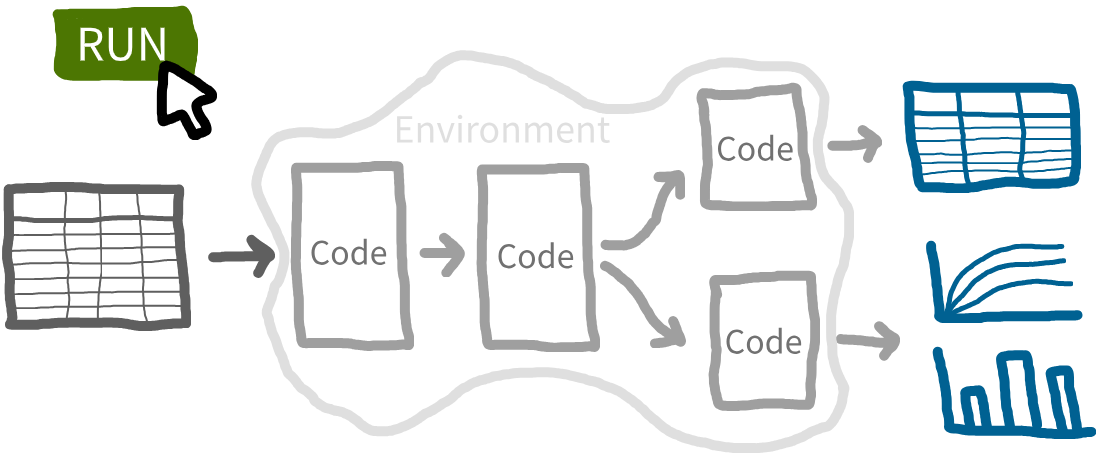
Reproducible Analytical Pipelines
RAP: Systematic approach. Every step (end-to-end) is transparent, automated and repeatable.
Discrete-event simulation (DES)
DES model a system as a sequence of events. For example, patients arriving, waiting, receiving treatment, and leaving.
Discrete-event simulation (DES)
DES incorporate uncertainty - instead of e.g., fixed frequency of arrivals, sample from statistical distribution.
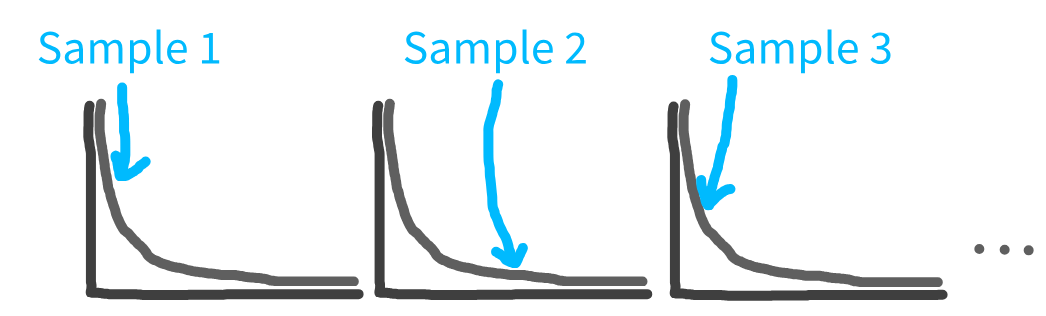
Discrete-event simulation (DES)
DES incorporate uncertainty - instead of e.g., fixed frequency of arrivals, sample from statistical distribution.
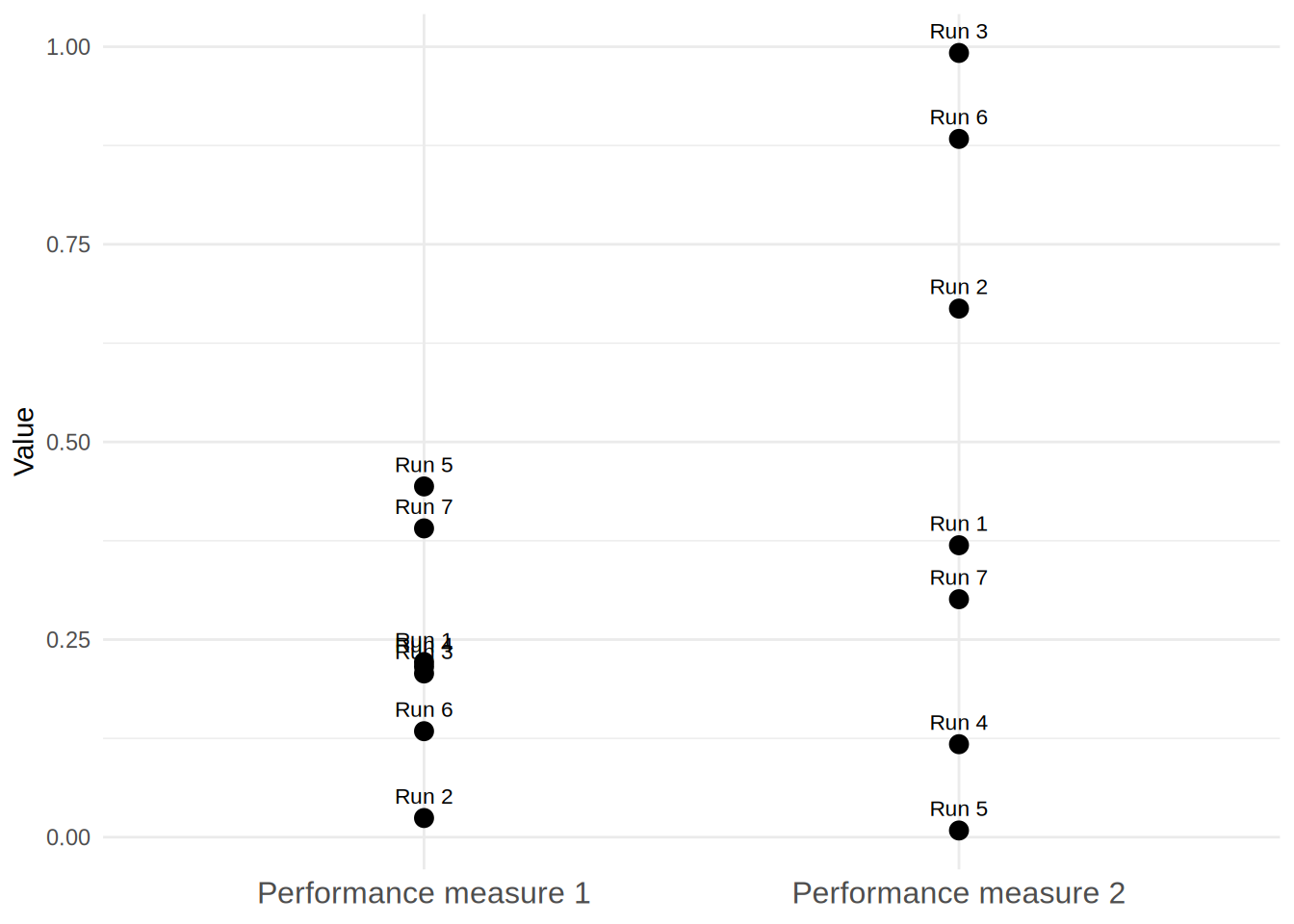
This means each run
produces different results.
How to construct DES as RAP?
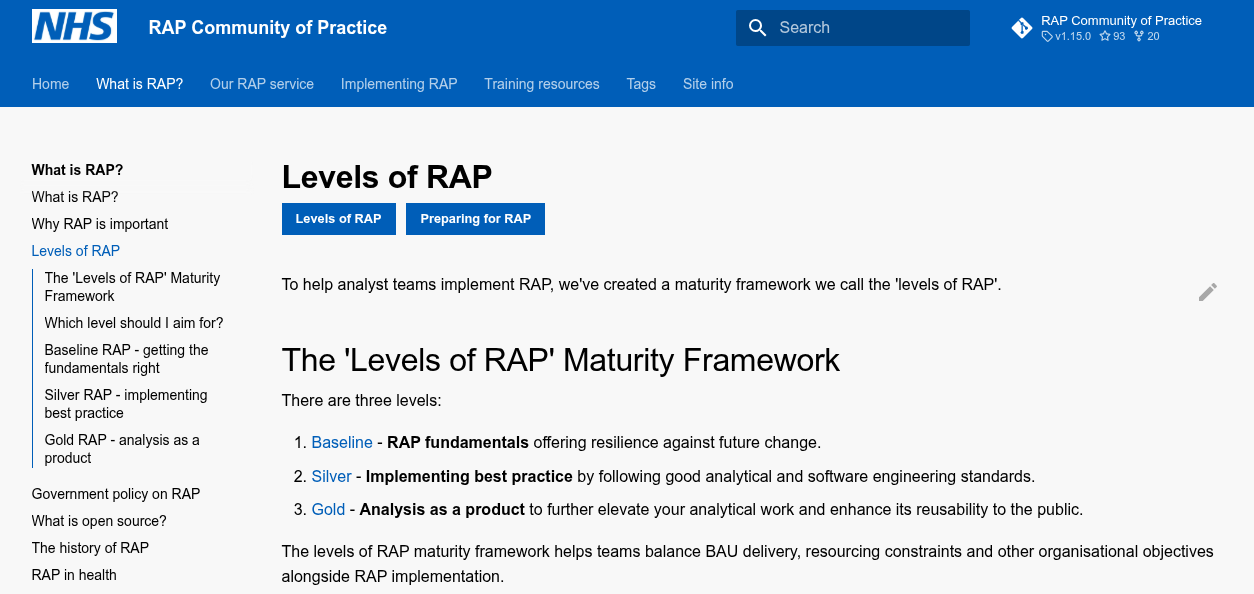
Resource 1: NHS Levels of RAP
How to construct DES as RAP?
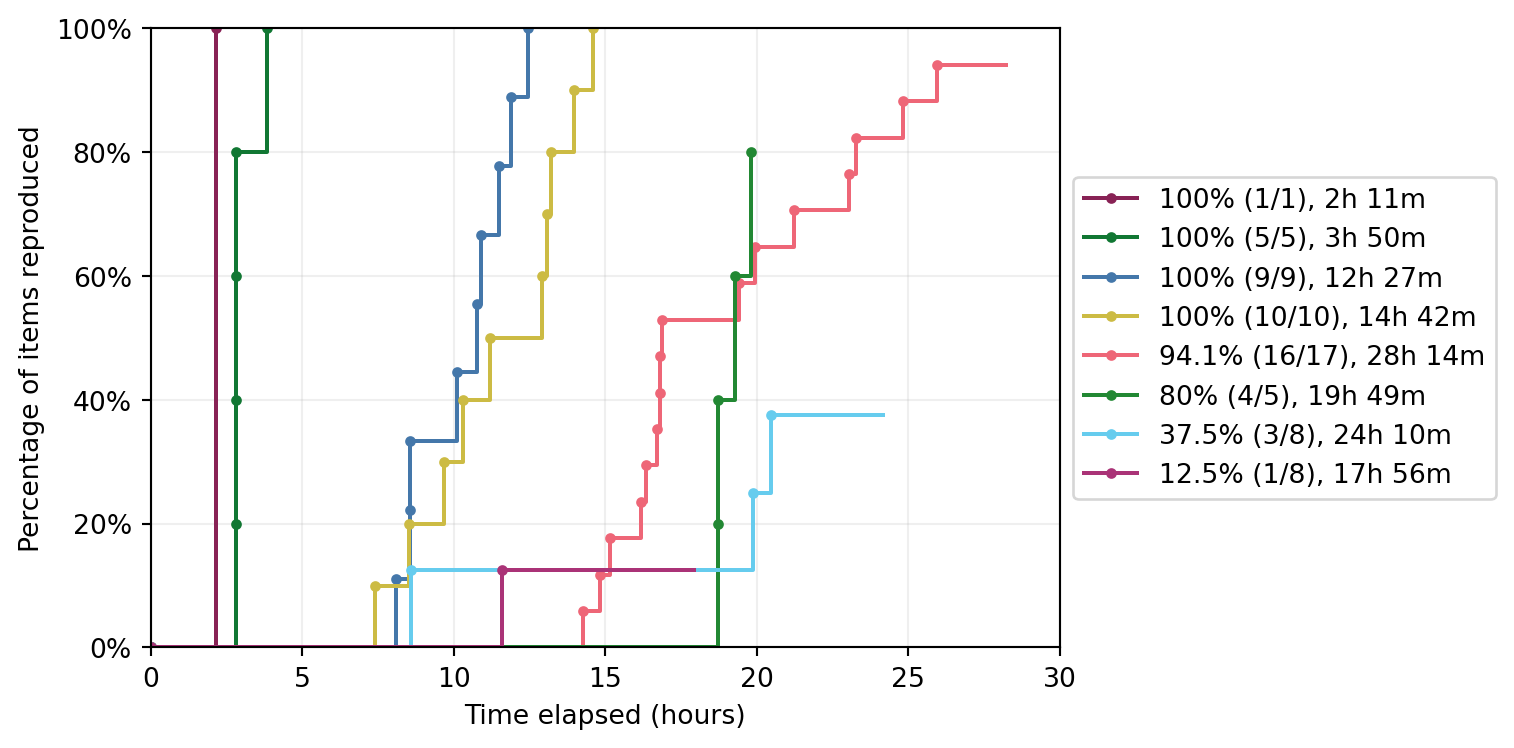
Resource 2: STARS DES reproducibility recommendations

How to construct DES as RAP?
Resource 2: DES reproducibility recommendations
How to construct DES as RAP?
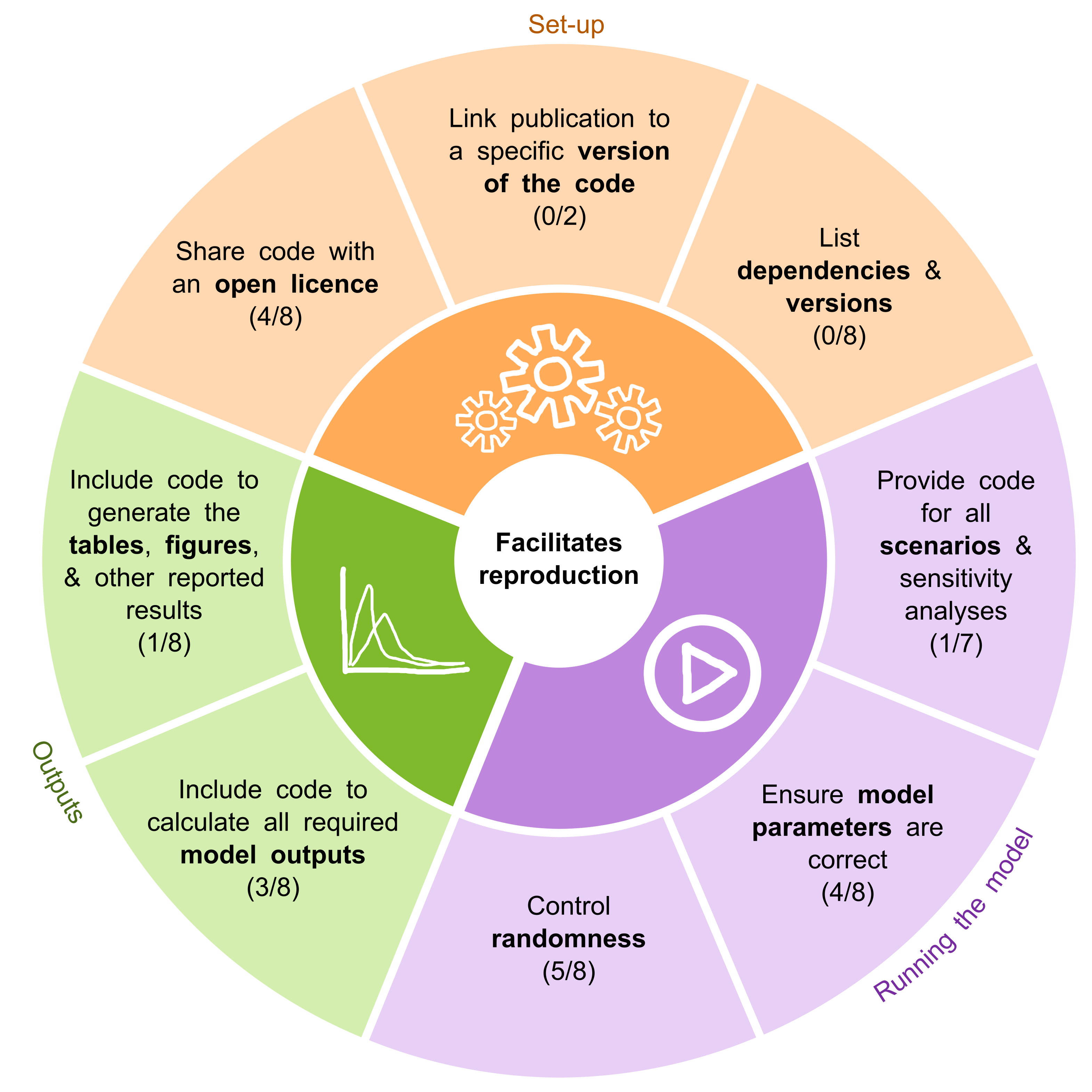
Resource 2: STARS DES reproducibility recommendations
How to construct DES as RAP?
Resource 2: STARS DES reproducibility recommendations
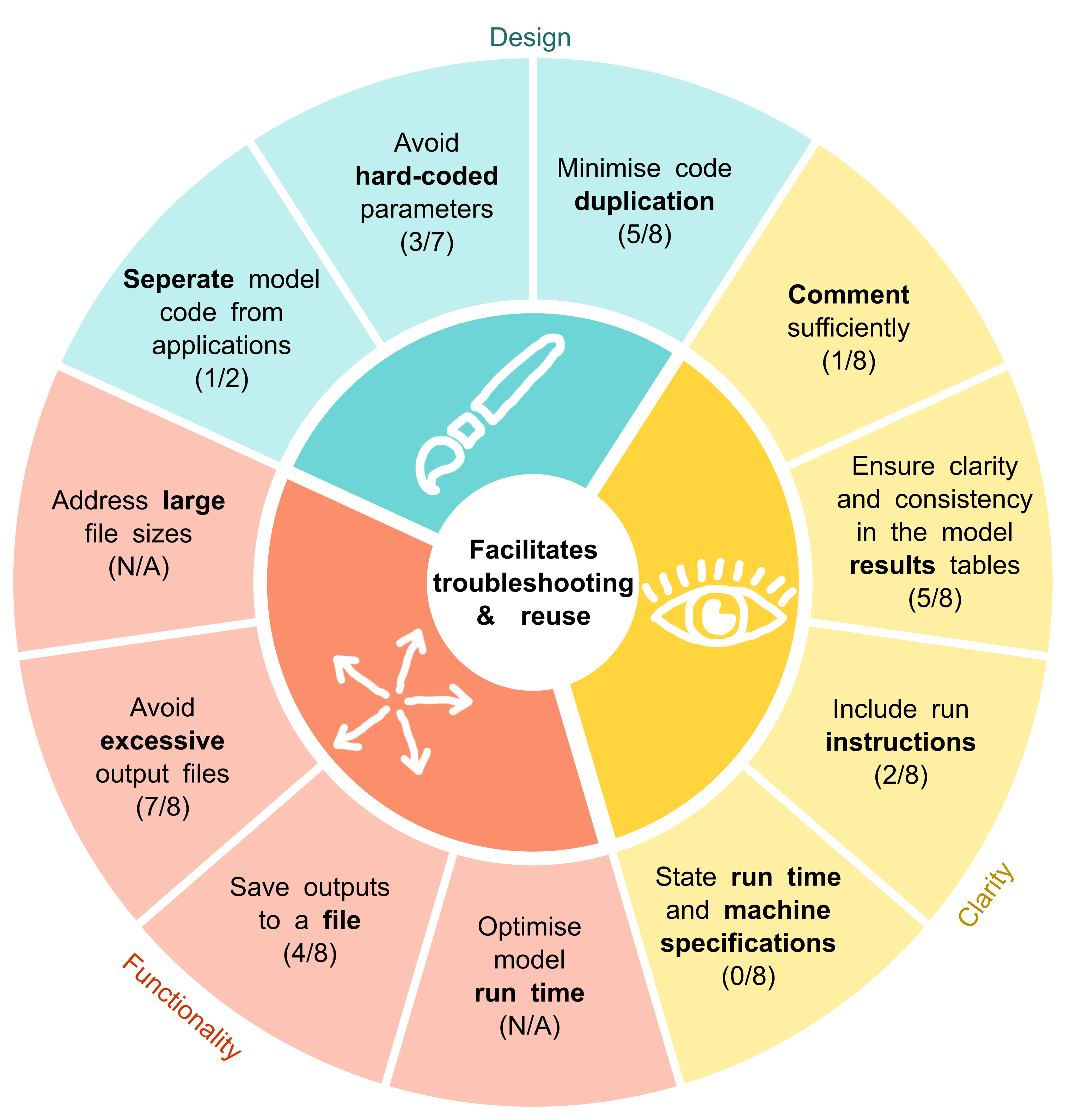
Focus of this webinar


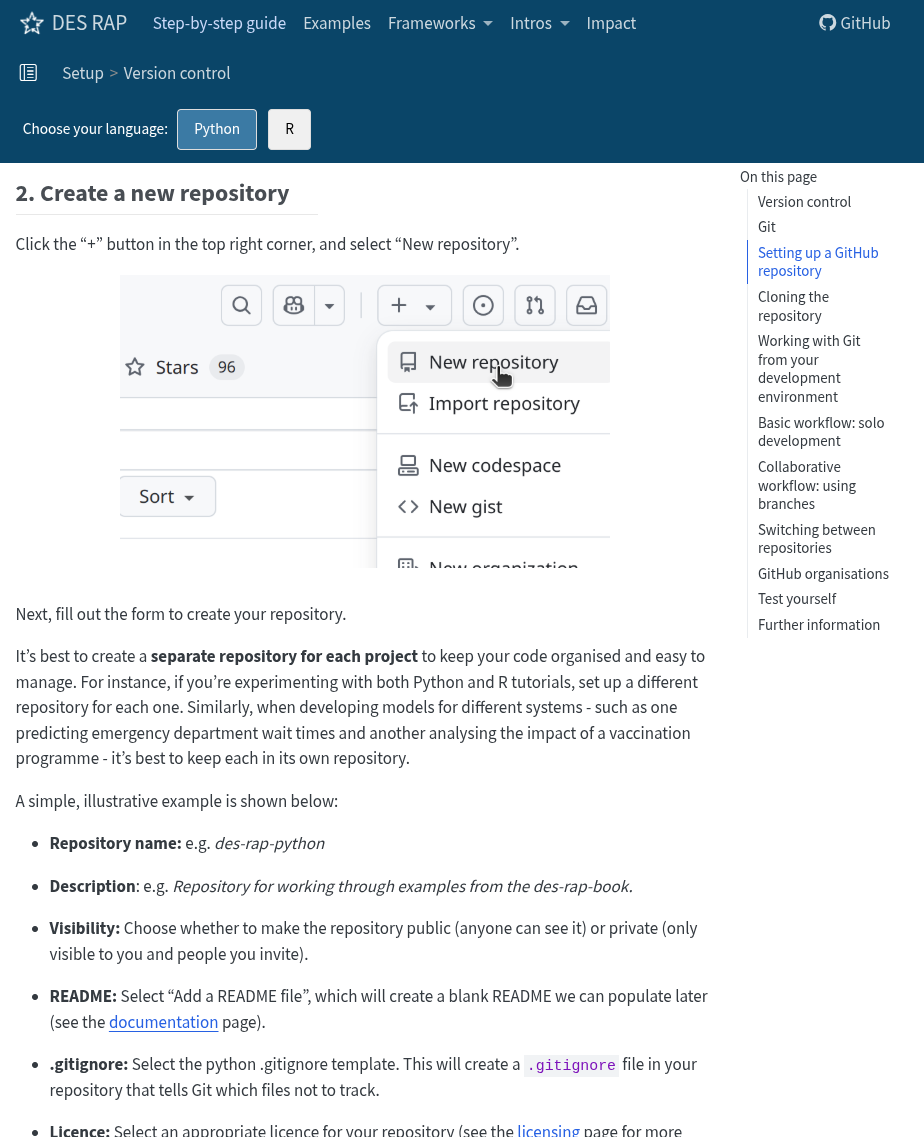
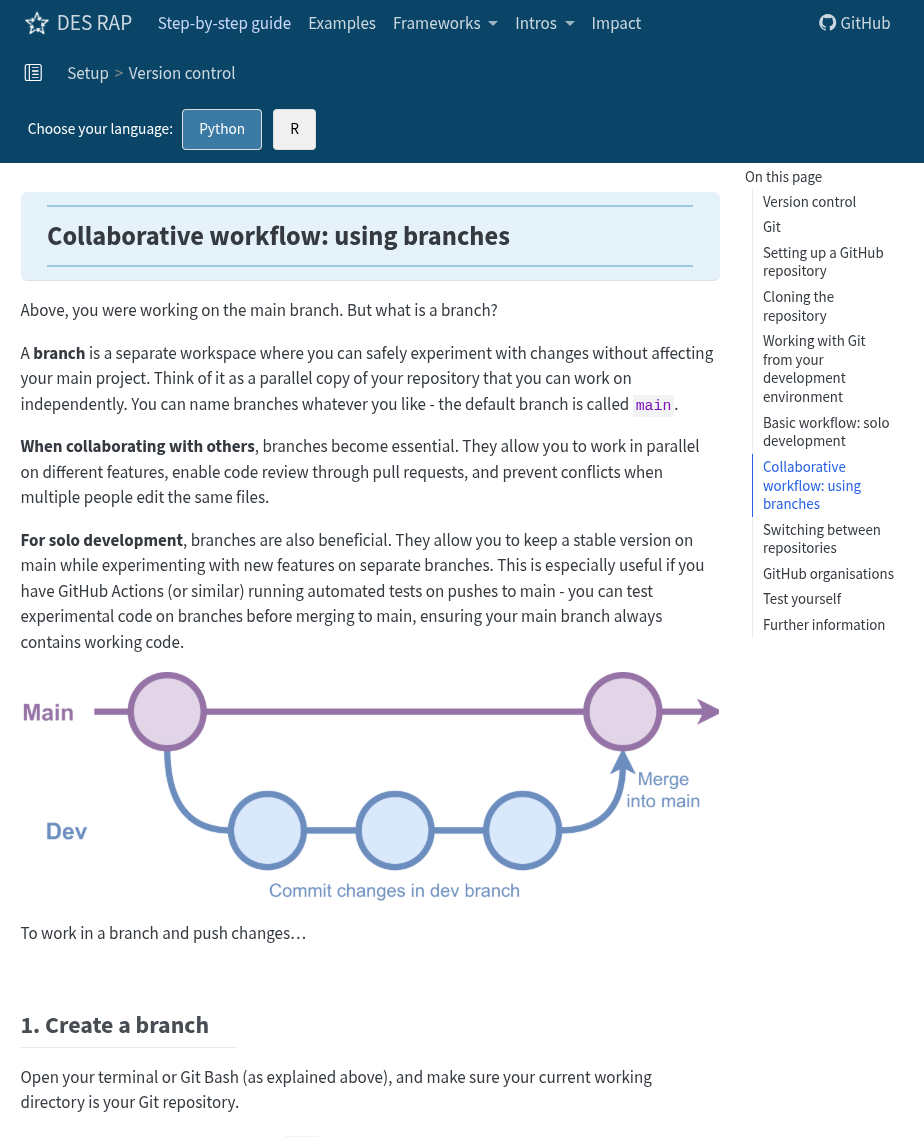
Version control: GitHub
Environments
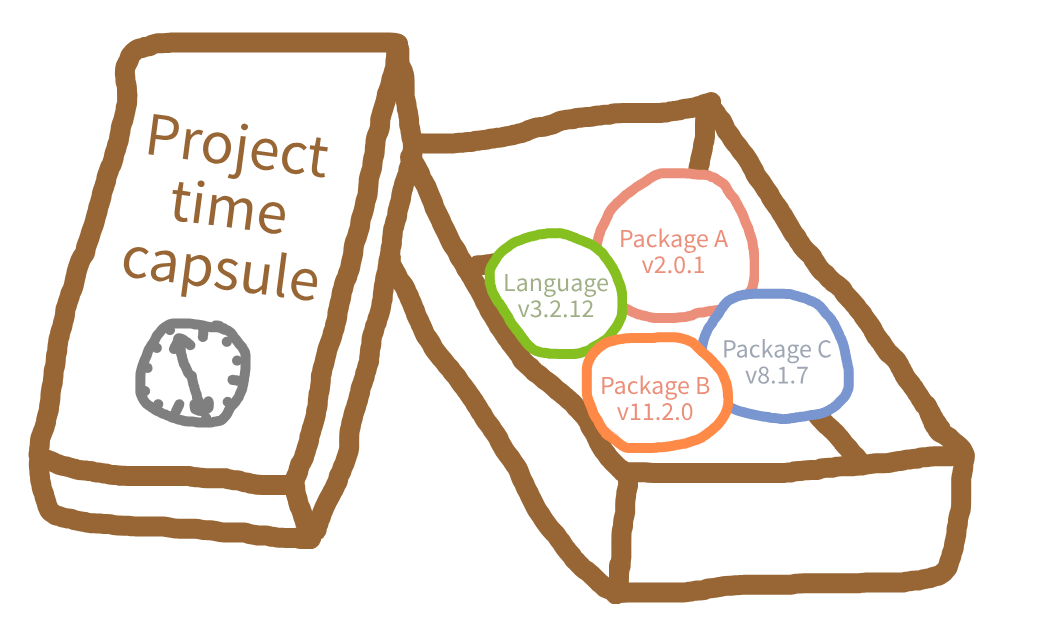
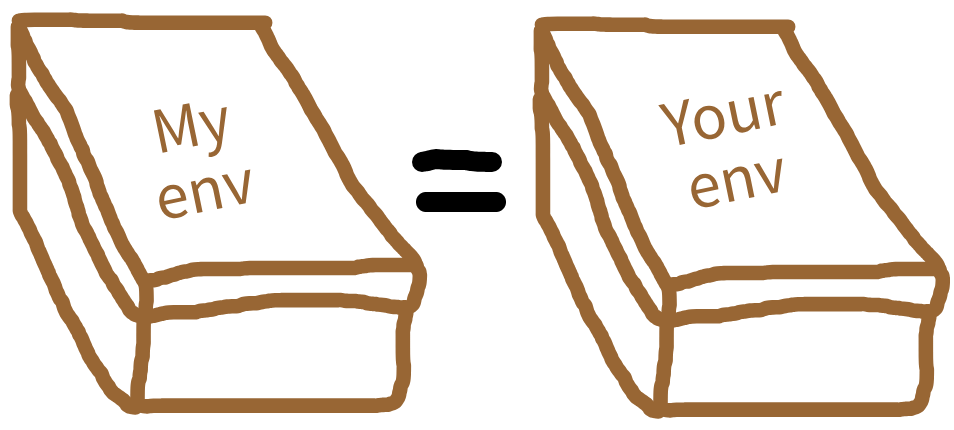

Structuring as a package
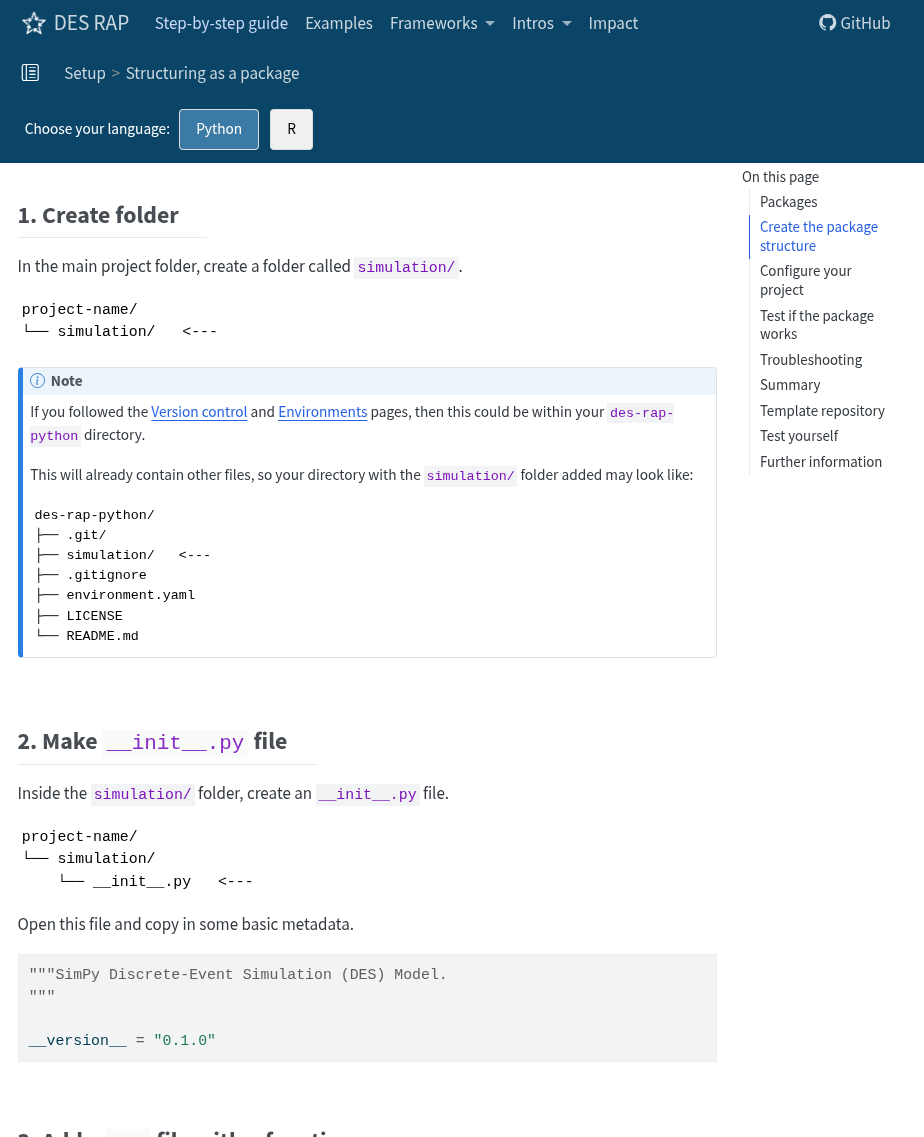
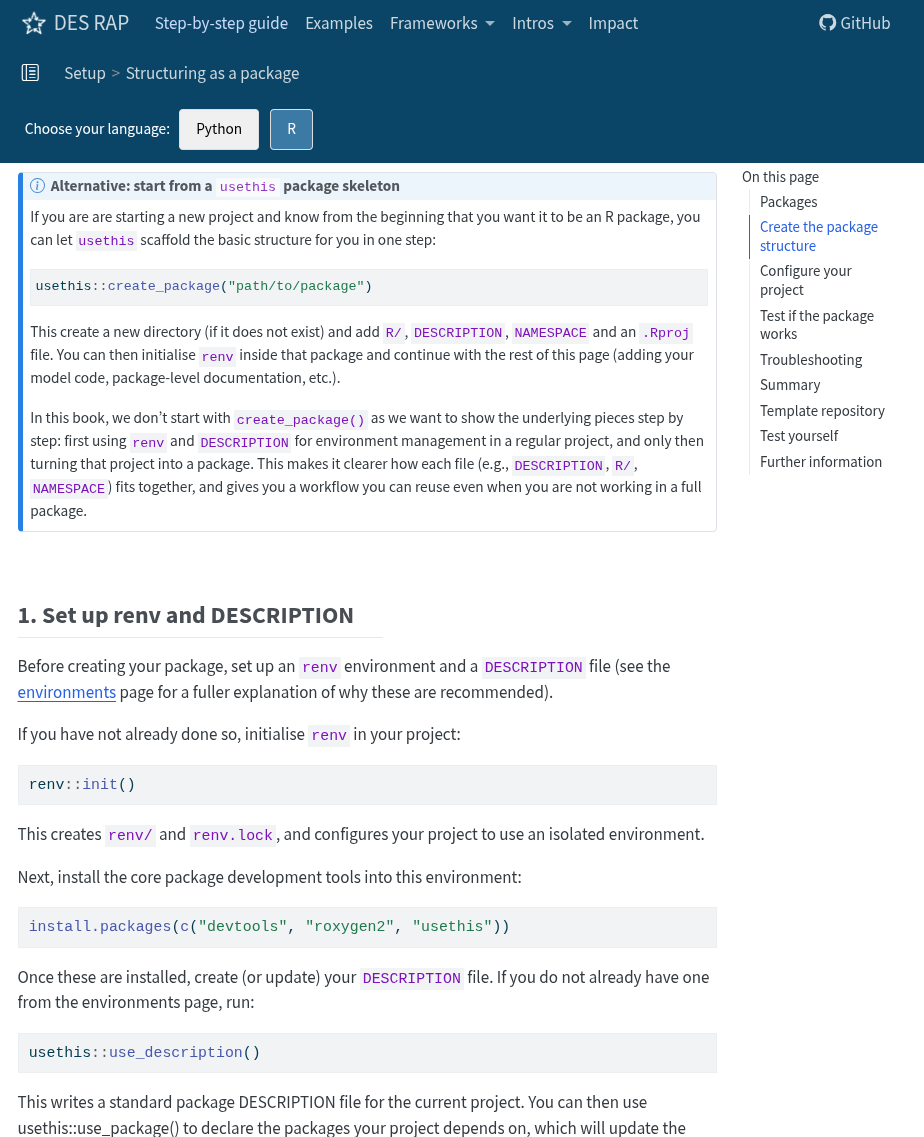
Structuring as a package
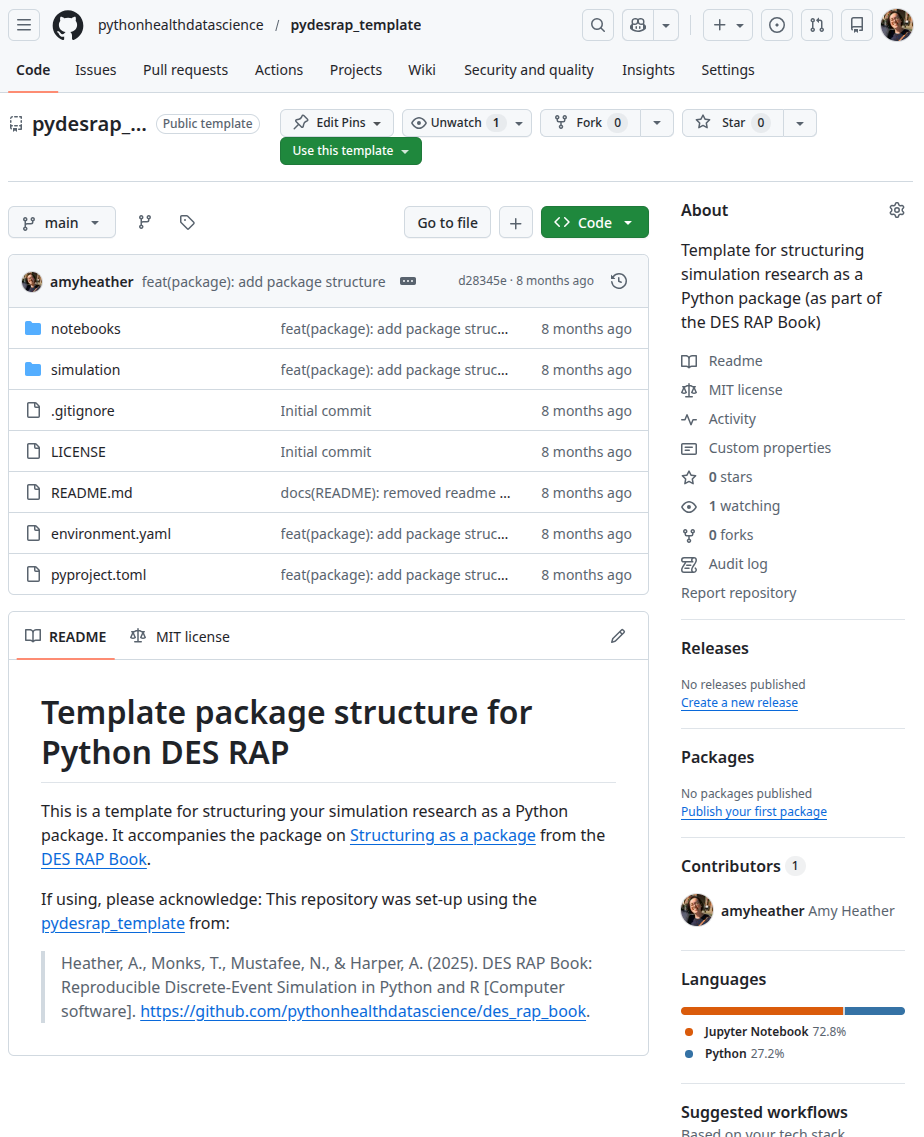
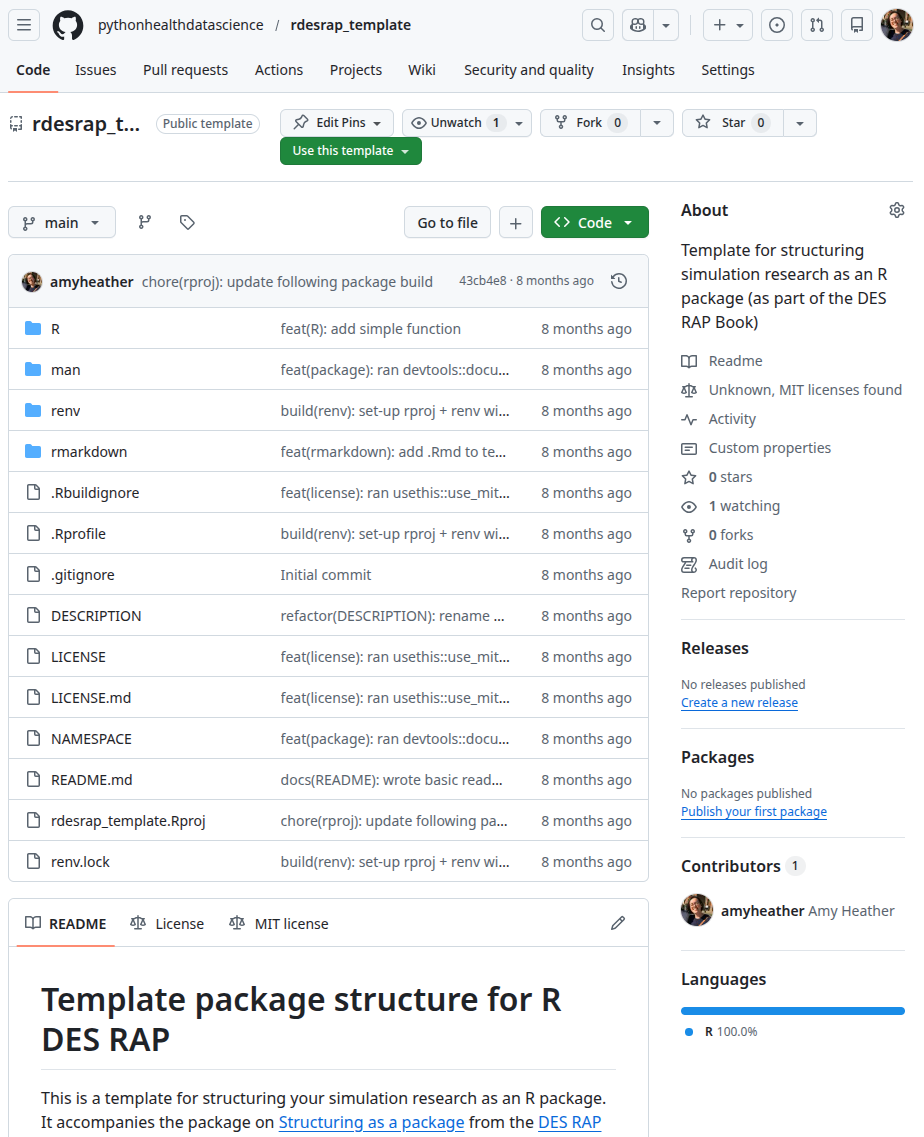
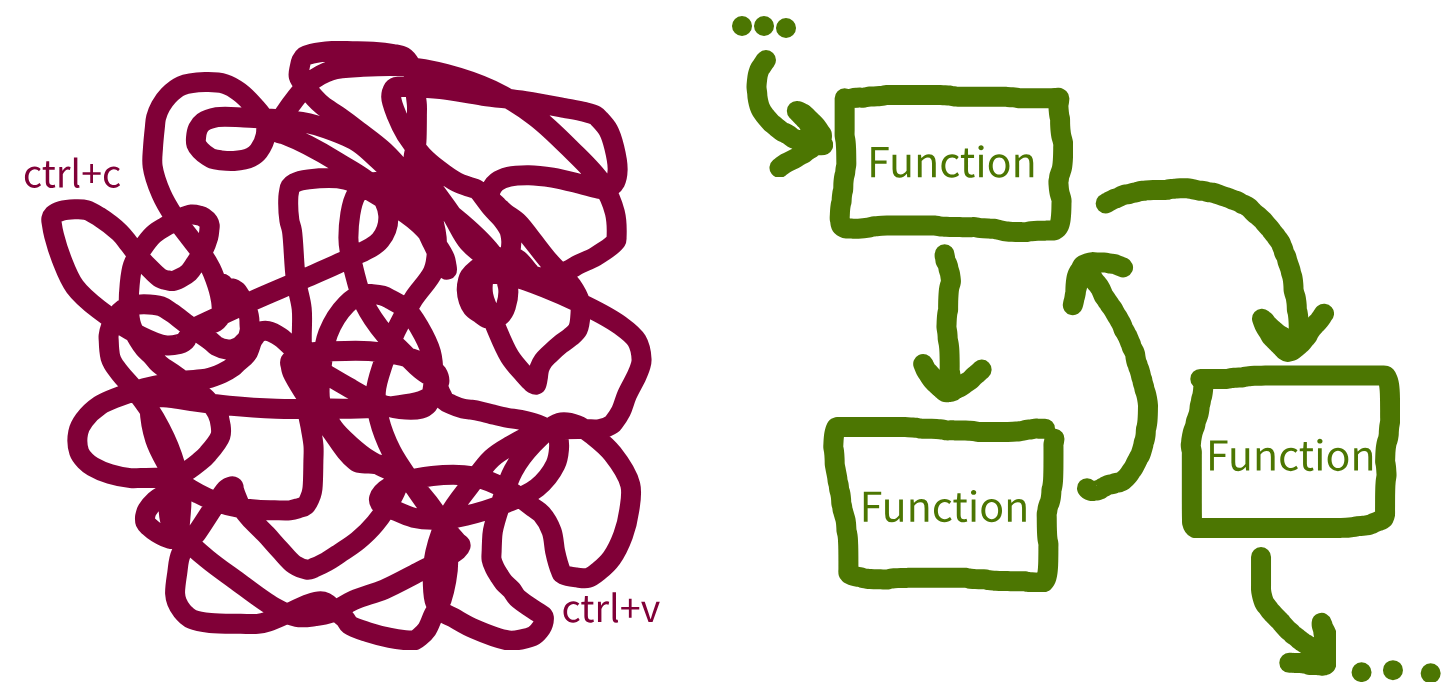
Code organisation
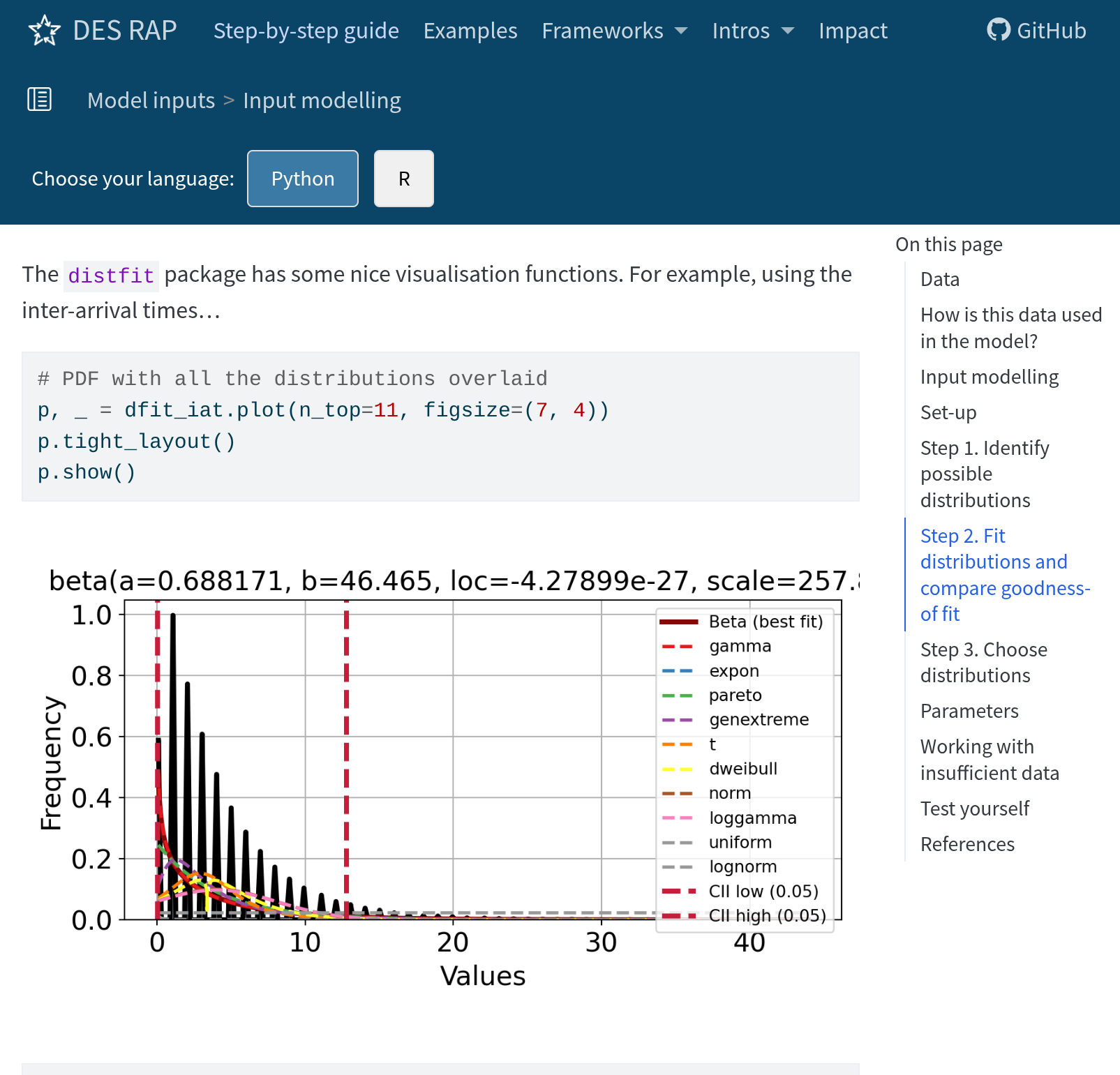
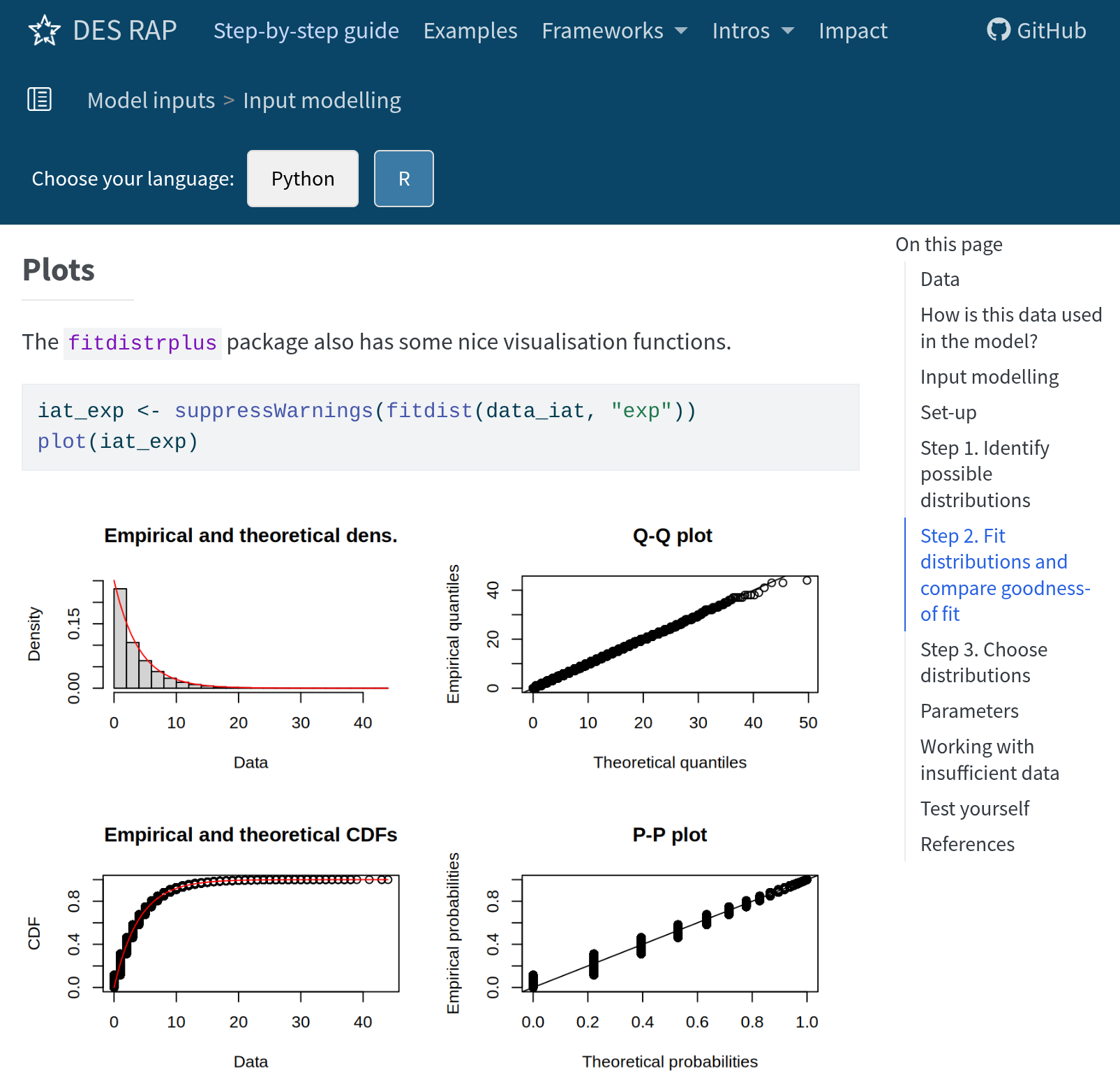
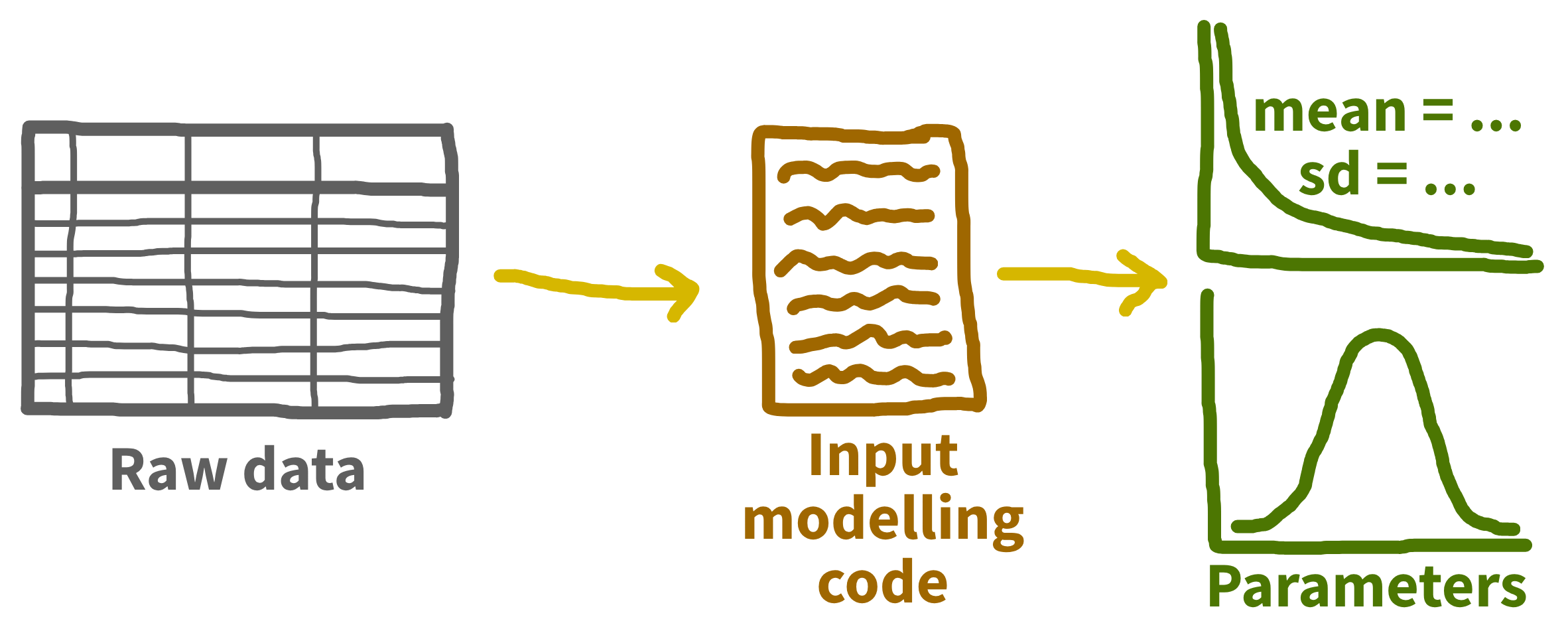
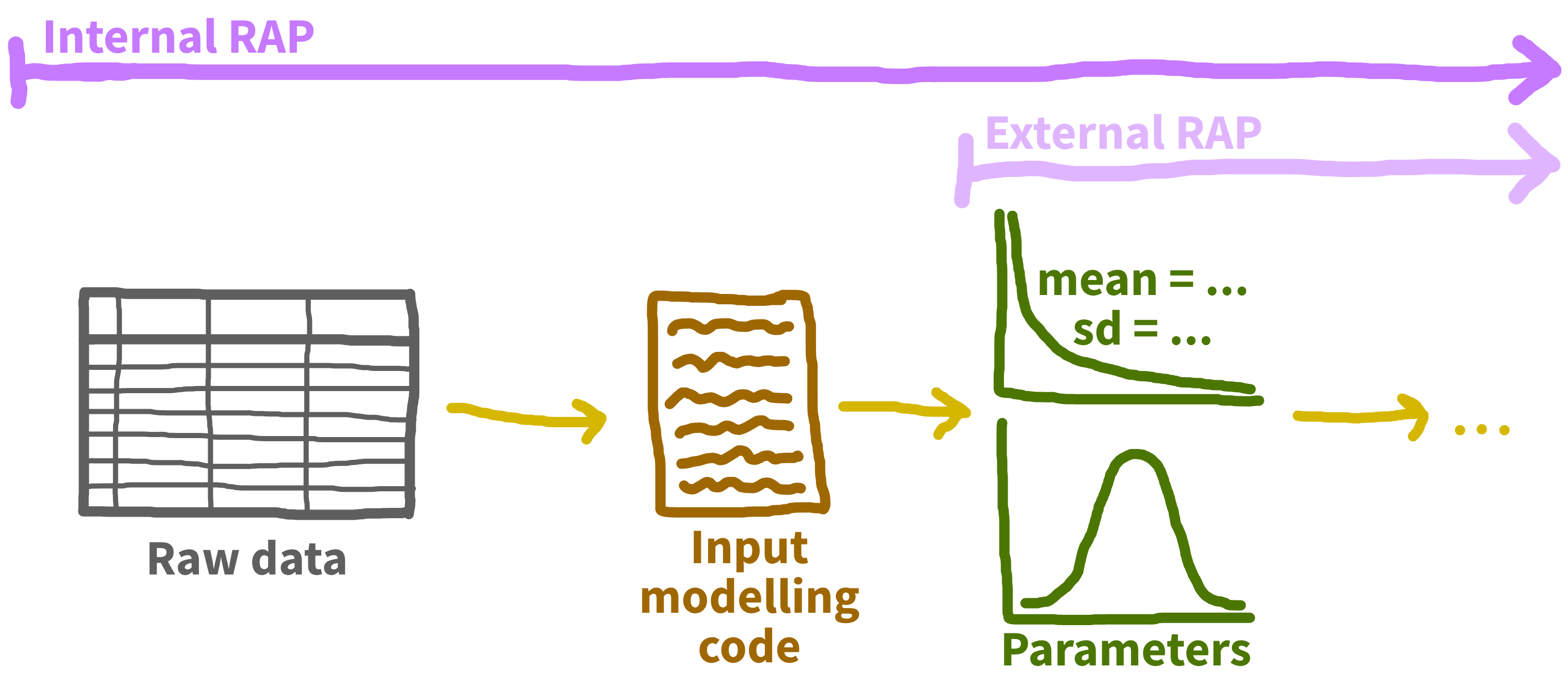
Input modelling
Recommend: distfit (Python) and fitdistrplus (R)
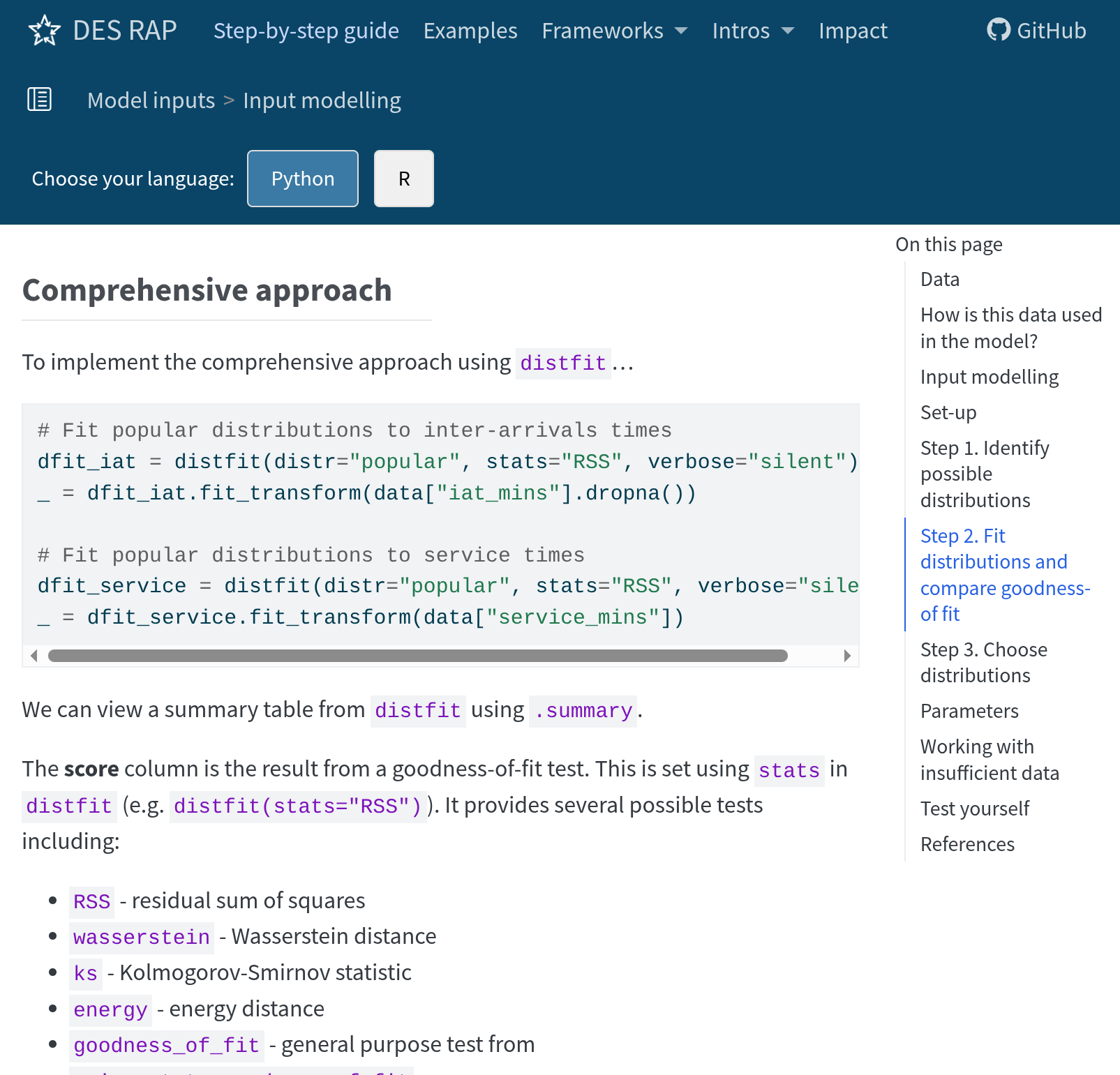
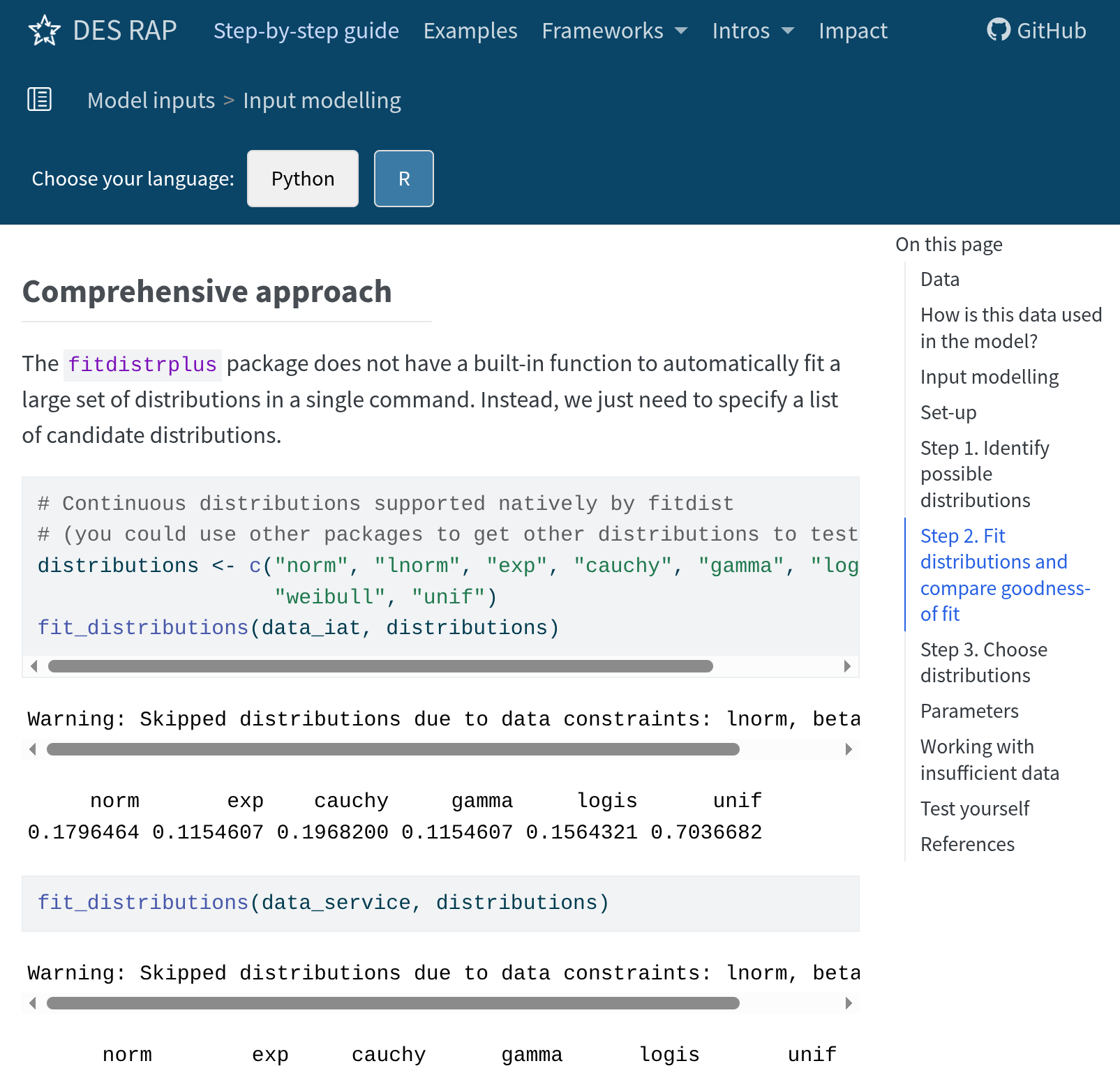
Input modelling
Recommend: distfit (Python) and fitdistrplus (R)
Input data management
Input data management
Randomness
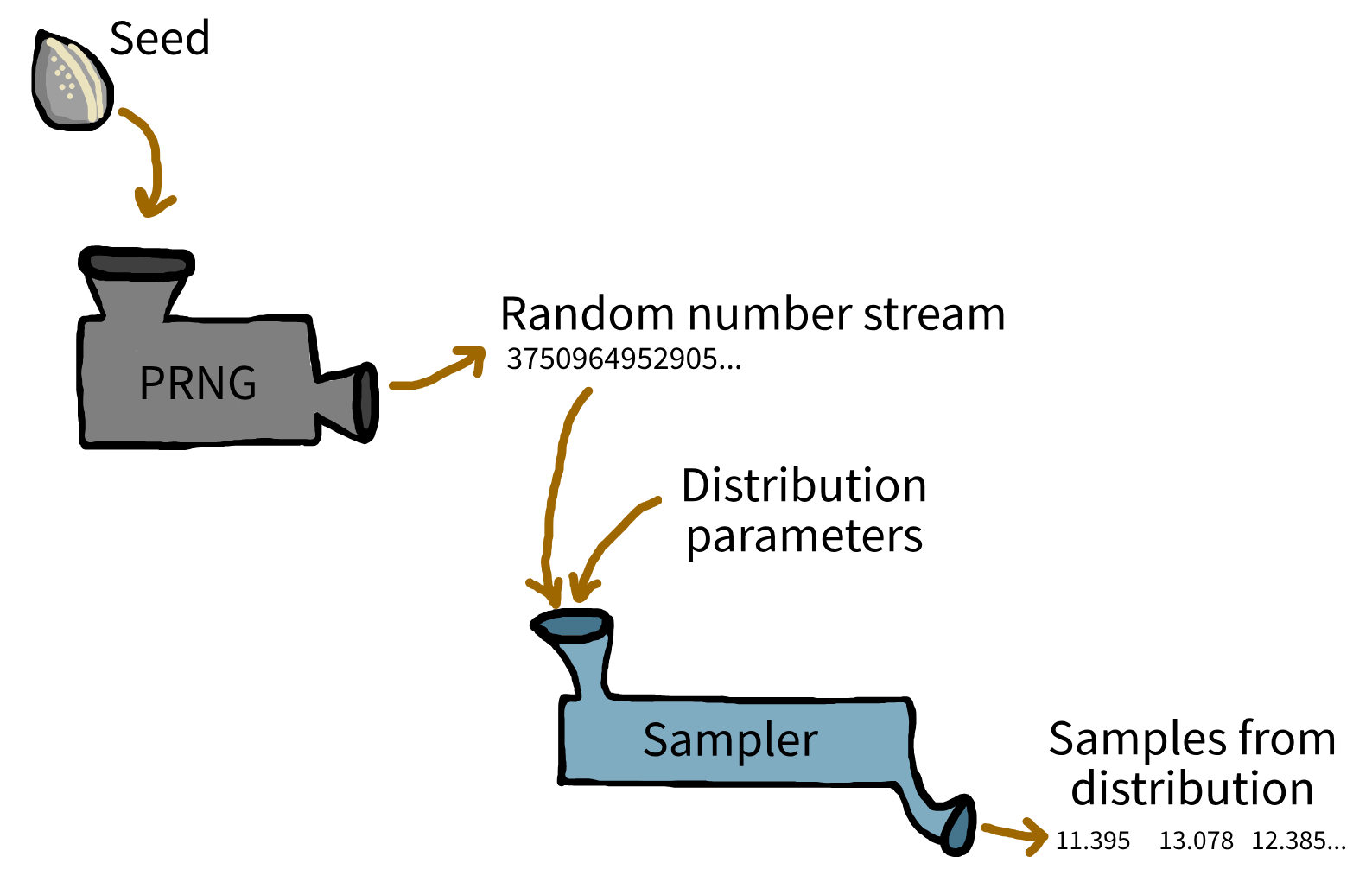
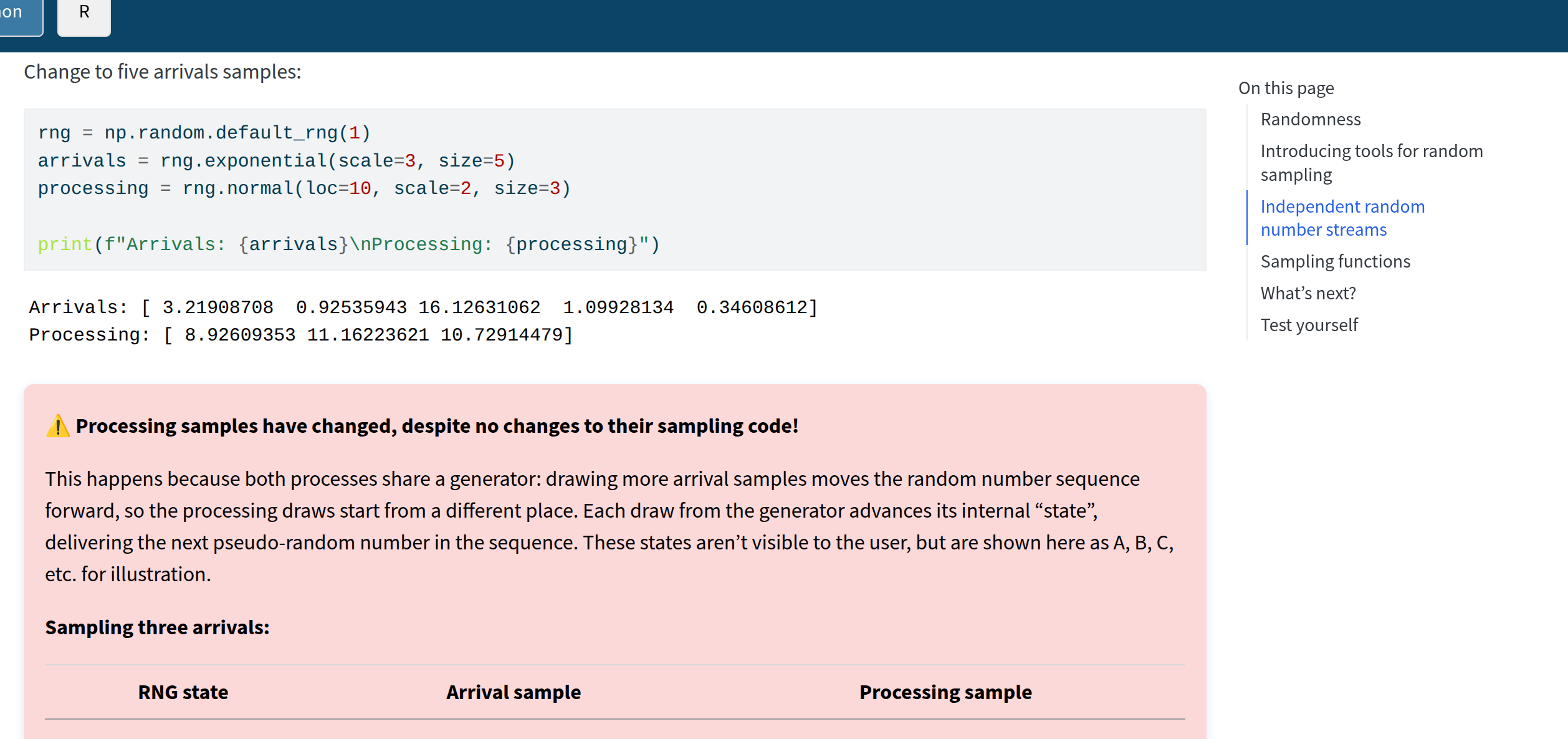
Randomness: Python
sim-tools can help with problem of shared random number generators.
Building a DES model
We guide through creating incrementally…


simpy (Python) and simmer (R)
Initialisation bias
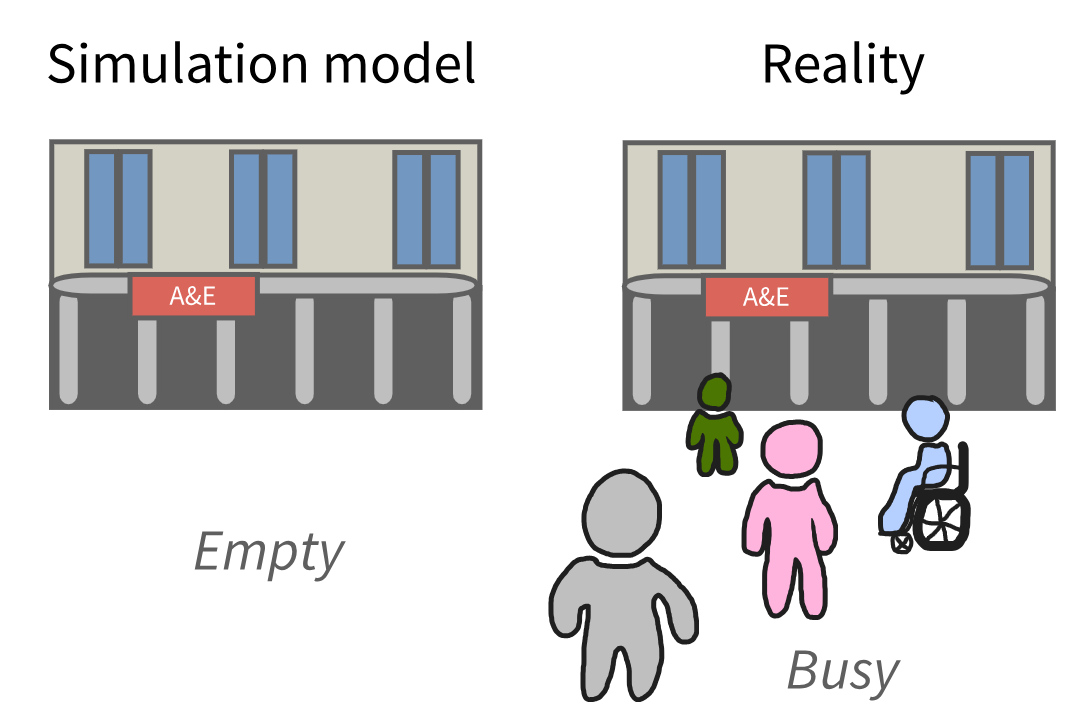
Initialisation bias
Two main strategies:
- Initial conditions: start with some entities/resources.
- Warm-up period: run model until it reaches a steady state.
Initialisation bias
Time series inspection approach.
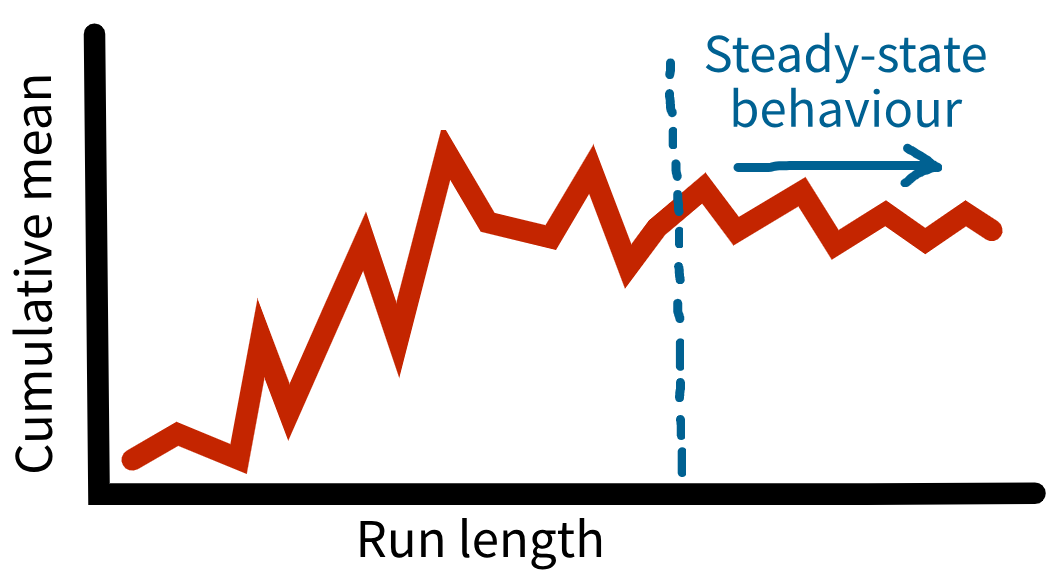
Initialisation bias
Time series inspection approach.
How?
- Record performance measures at regular intervals.
- Run multiple replications and long run length.
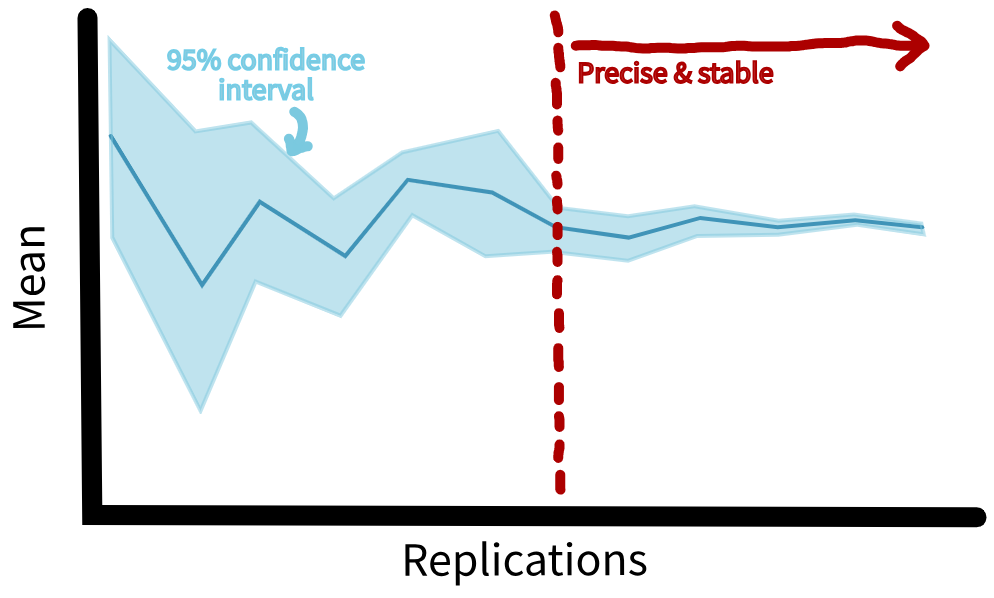
Replications
Replications
Confidence interval method - manual or automated.
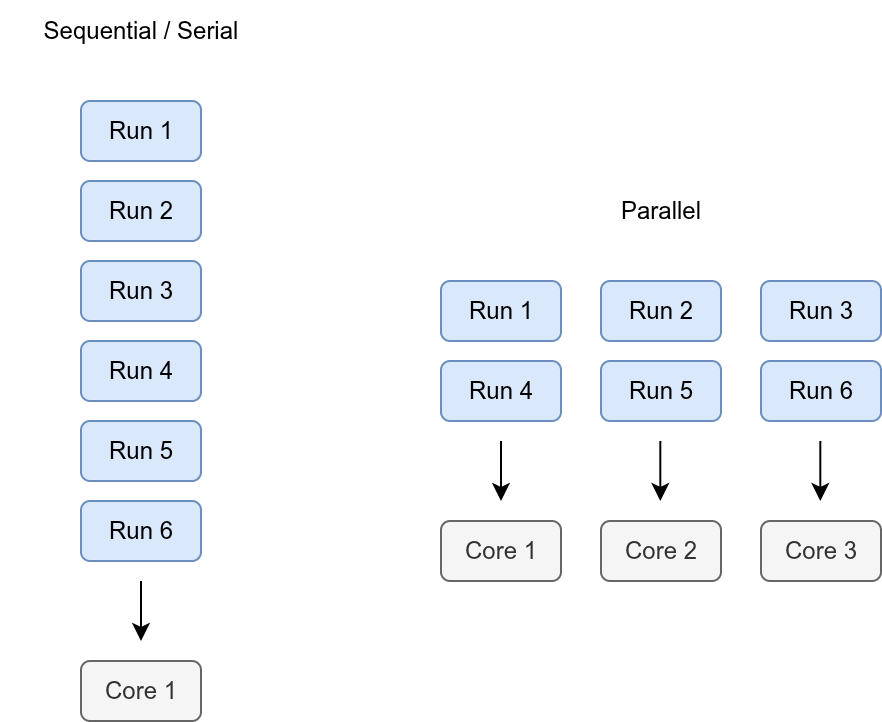
Parallel processing
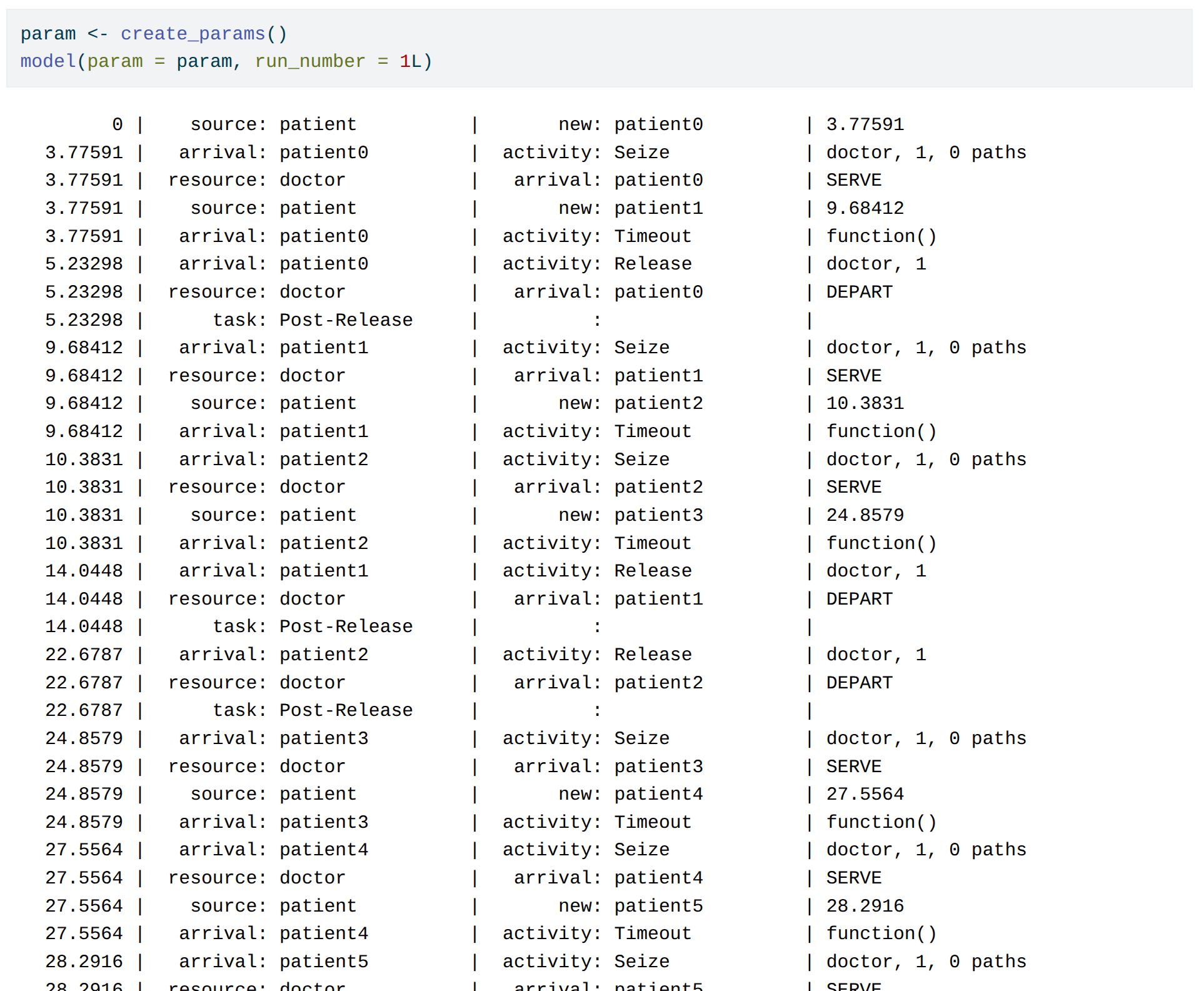
Logging (R)
Run simmer with verbose = TRUE:
Logging (R)
Custom logs using simmer::log_():
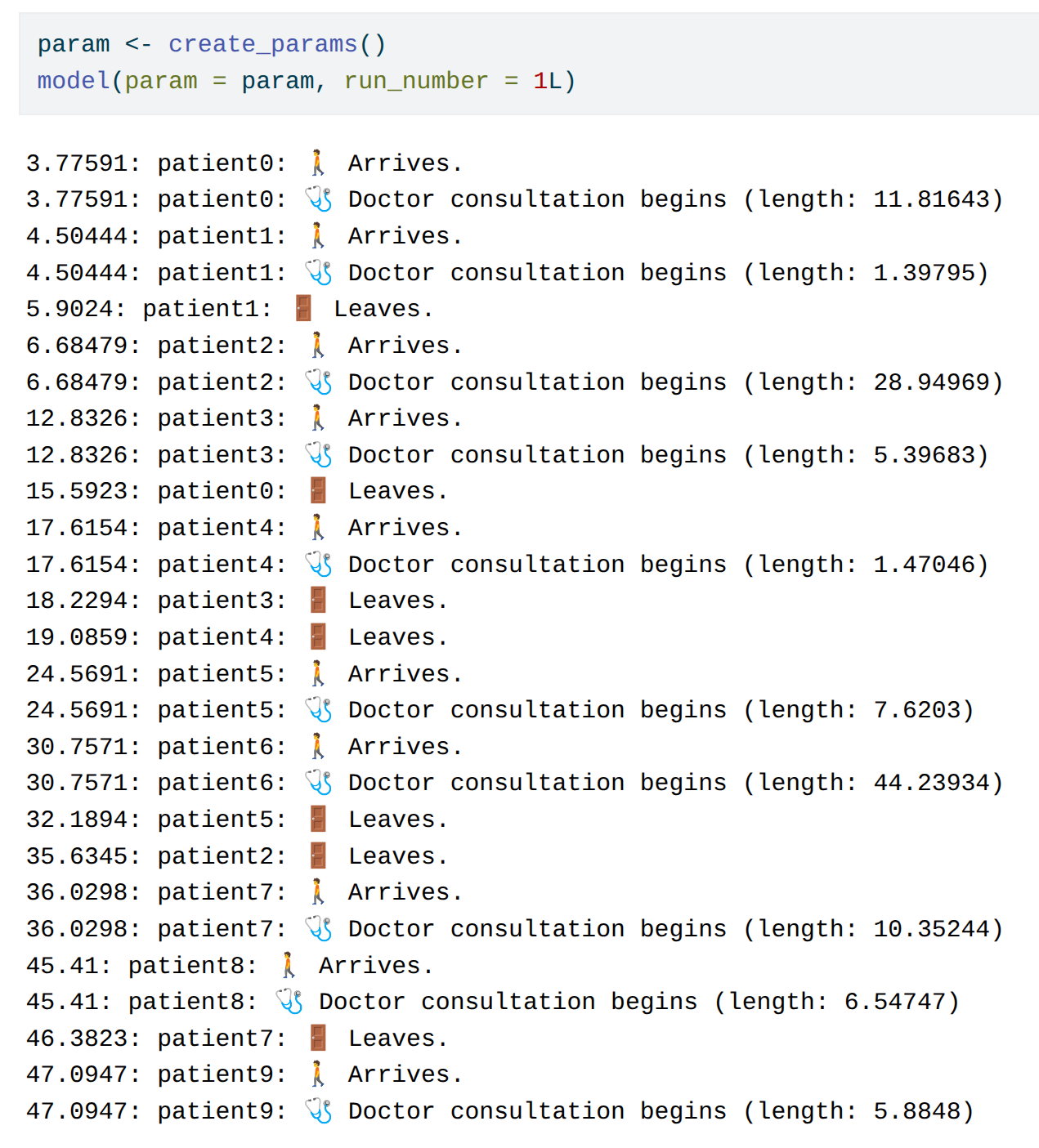
Modular model structure
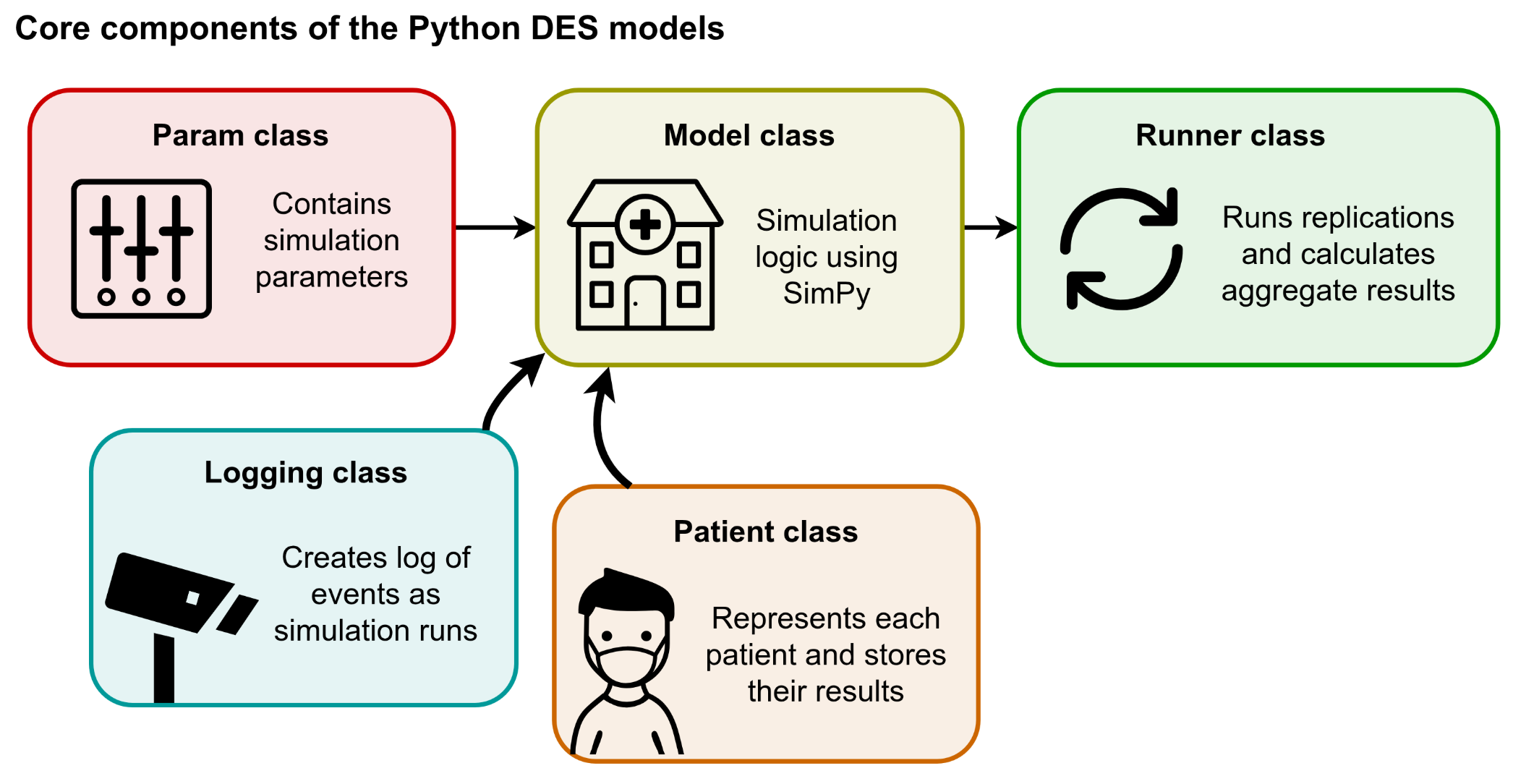
Modular model structure
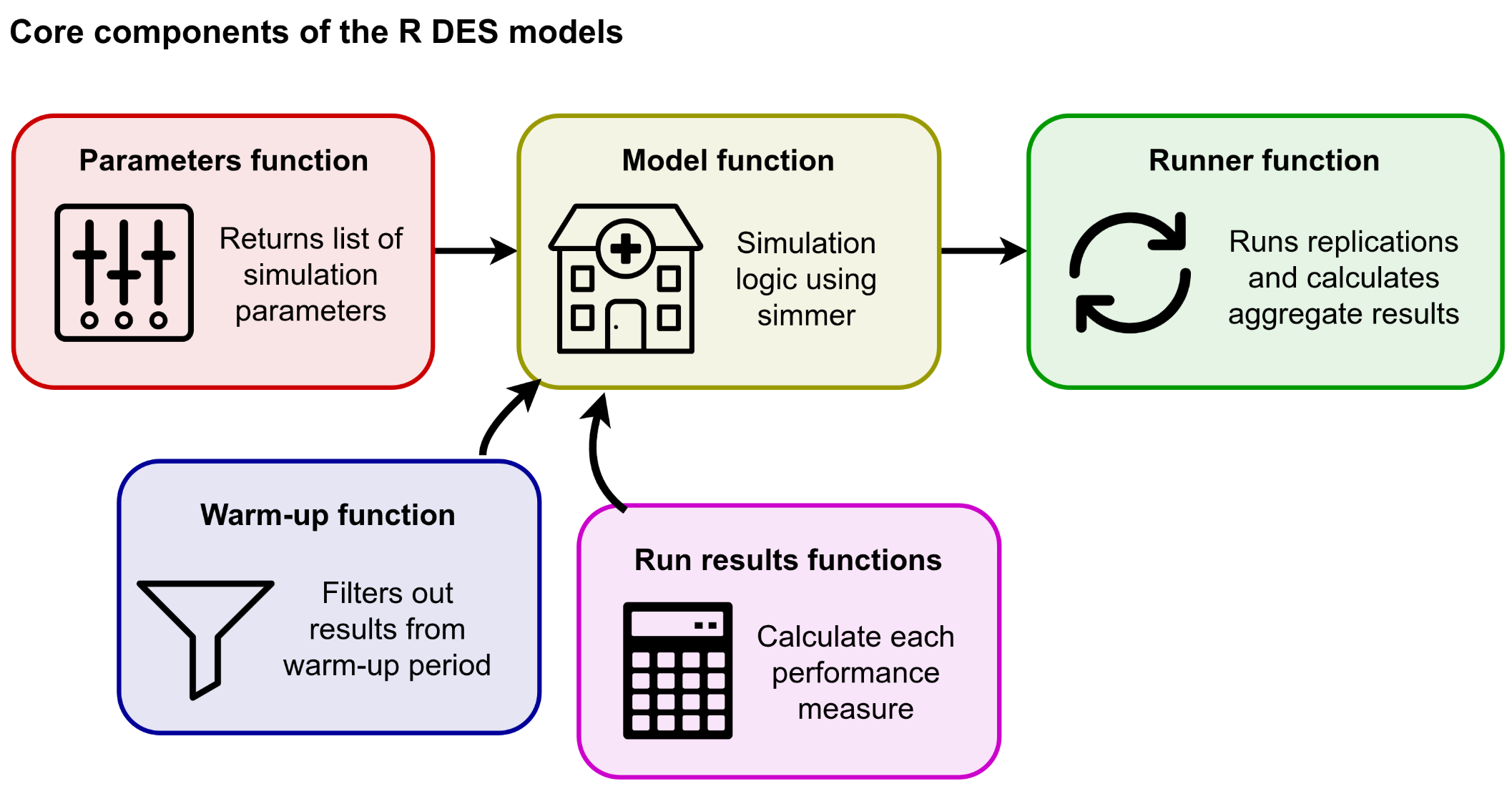
Full run
Relevant guidelines:
- STARS Reproducibility Recommendations (⭐): Ensure model parameters are correct.
- NHS Levels of RAP (🥈): Outputs are produced by code with minimal manual intervention.
Verification and validation
Verification: The process of checking that the simulation model correctly implements the intended conceptual model.
It involves checking that the model’s logic, structure and parameters are implemented as planned and free from coding errors.

Verification and validation
Validation: The process of checking whether the simulation model is a sufficiently accurate representation of your real system.
It involves comparing the model’s inputs, behaviour and results to the real system

Tests
Guidance in DES RAP Book - and in our other resource:
https://pythonhealthdatascience.github.io/stars-testing-intro/
Quality assurance
Quality assurance (QA) is the formal, systematic process of ensuring your analysis meets appropriate standards of quality and is suitable for its intended use. It means planning how you will check the work, carrying out those checks, and keeping clear evidence of what you did.
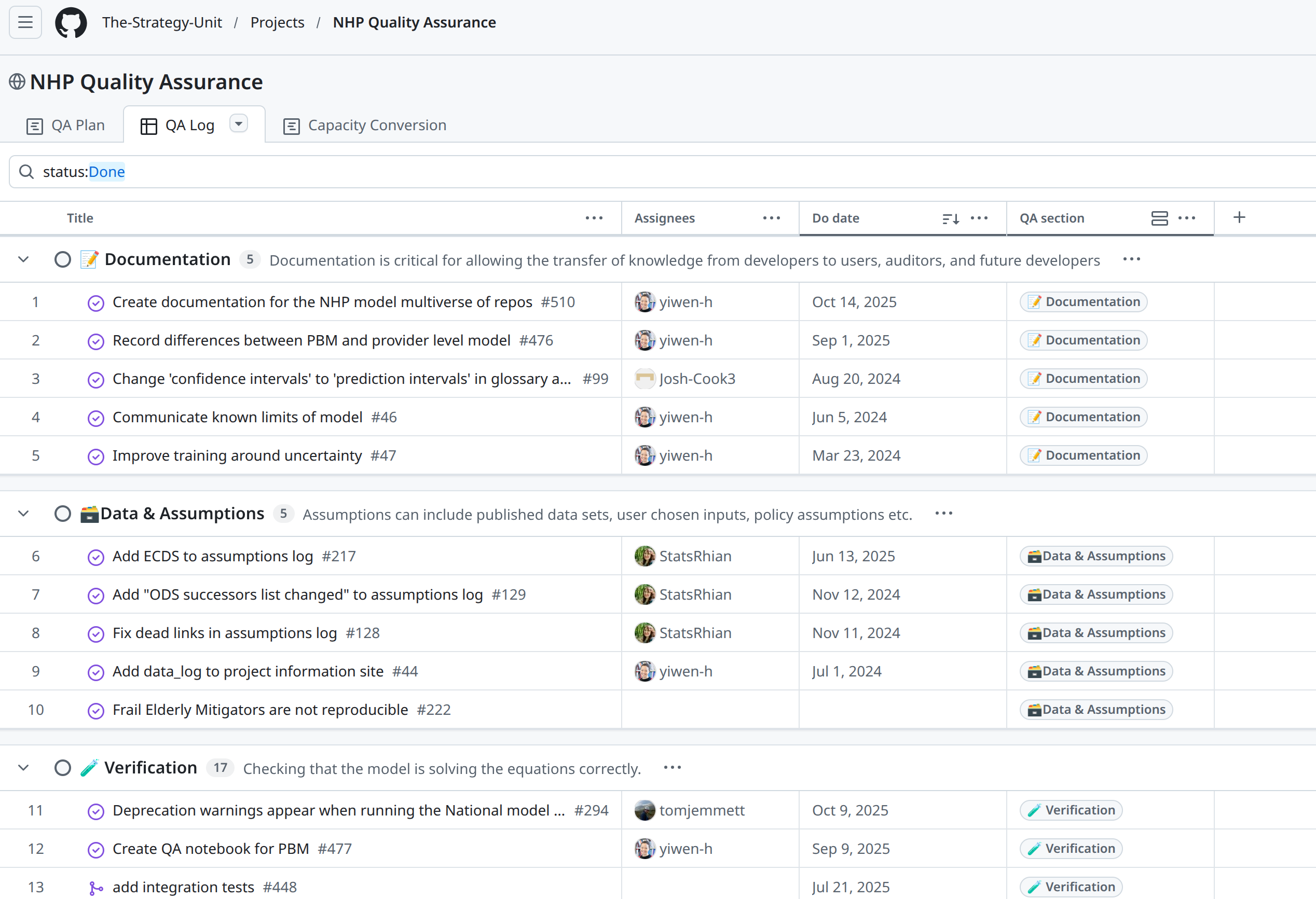
Quality assurance
Example: QA in the New Hospital Programme (The Strategy Unit).
Linting: style guides
Set of rules and conventions for writing code.

Linting: style guides
Set of rules and conventions for writing code.
Popular examples in Python:
Popular examples in R:
Linting: linters
Analyse code for possible errors and style issues.

Linting: linters
Analyse code for possible errors and style issues.
Linting: code formatters
Automatically format your code.
Linting: code formatters
Automatically format your code.
Linting: Quarto
Documentation: README.md
| Badge | Markdown |
|---|---|
[](https://github.com/pythonhealthdatascience/des_rap_book/blob/main/LICENSE) |
|
[](https://doi.org/10.5281/zenodo.17094155) |
|
[](https://orcid.org/0000-0002-6596-3479) |
|
 |
|
[](https://github.com/pythonhealthdatascience/pydesrap_stroke/actions/workflows/lint.yaml) |
Documentation: README.md
All Contributors - https://allcontributors.org/
Documentation: Website
Documentation: Website
Code review
Review pull requests:
Code review
Use GitHub issues.
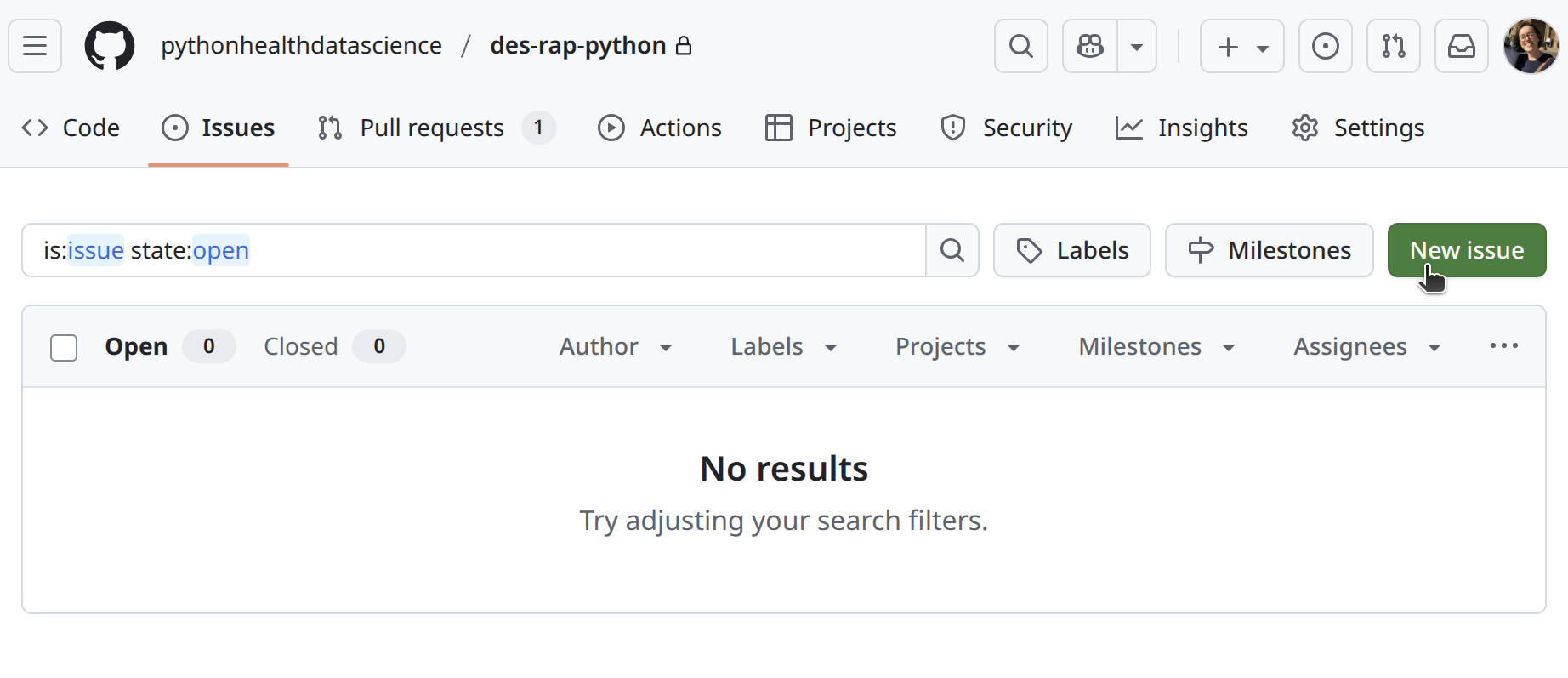
Cool things: (1) issue templates, (2) checklists, (3) sub-issues, (4) GitHub projects.
Licensing
For code:

For text:
Citation: CITATION.cff
https://citation-file-format.github.io/cffinit/
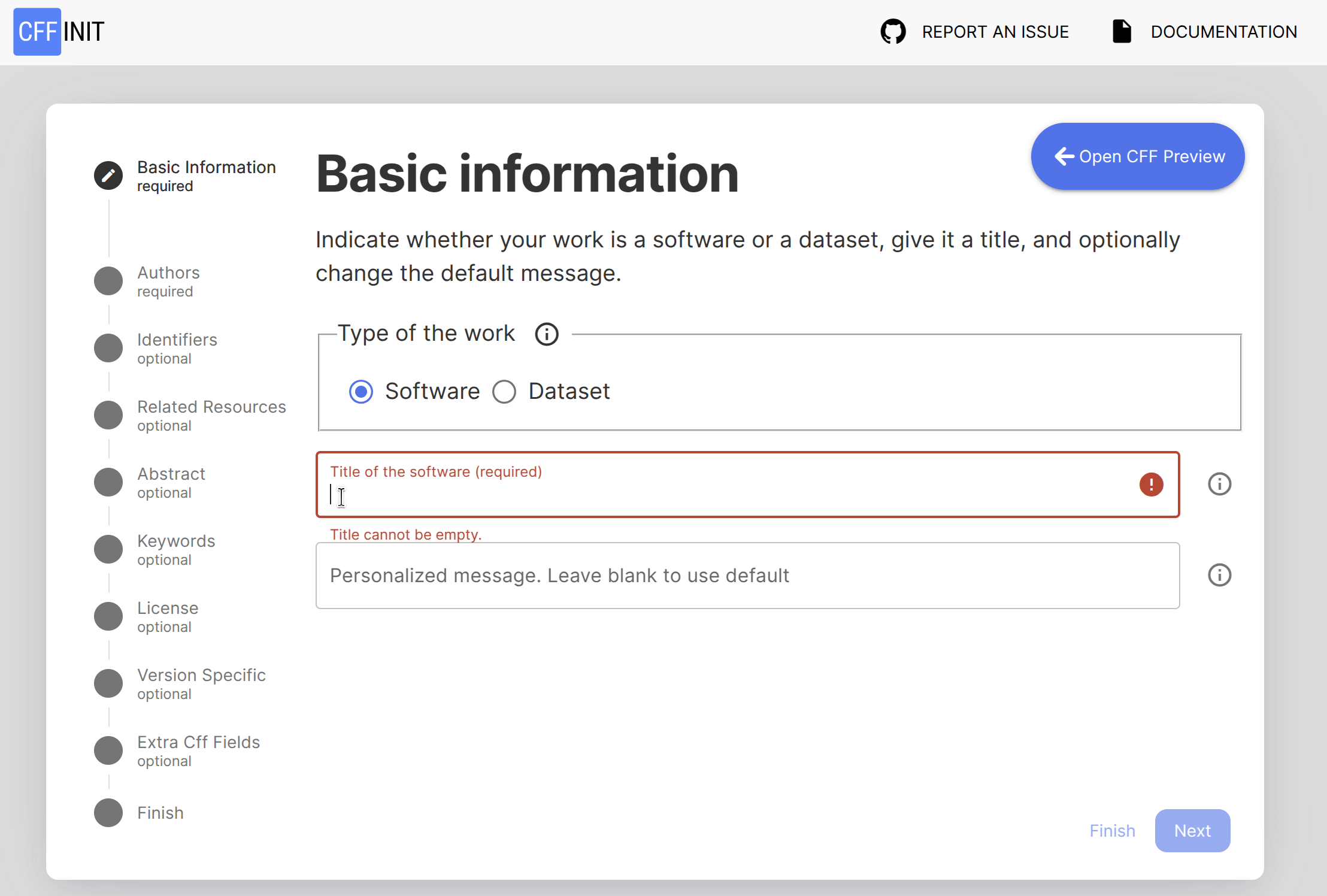
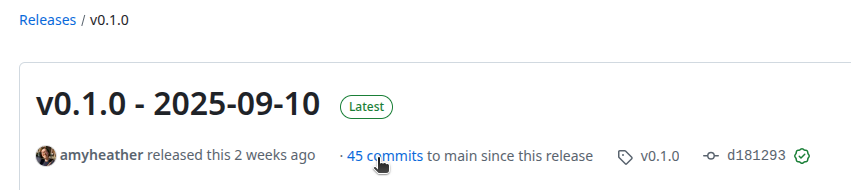
Changelog: GitHub releases
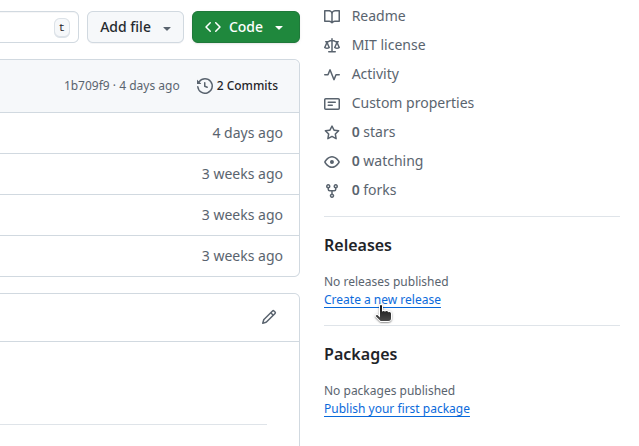
Changelog: GitHub releases
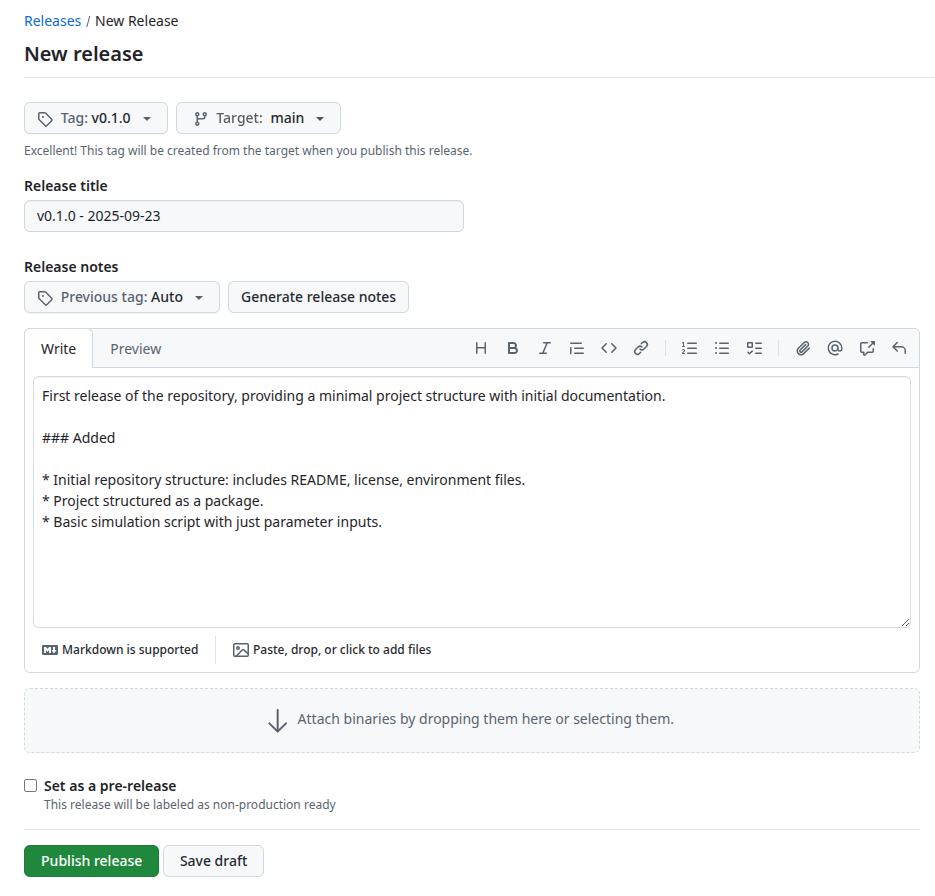
Changelog: GitHub releases
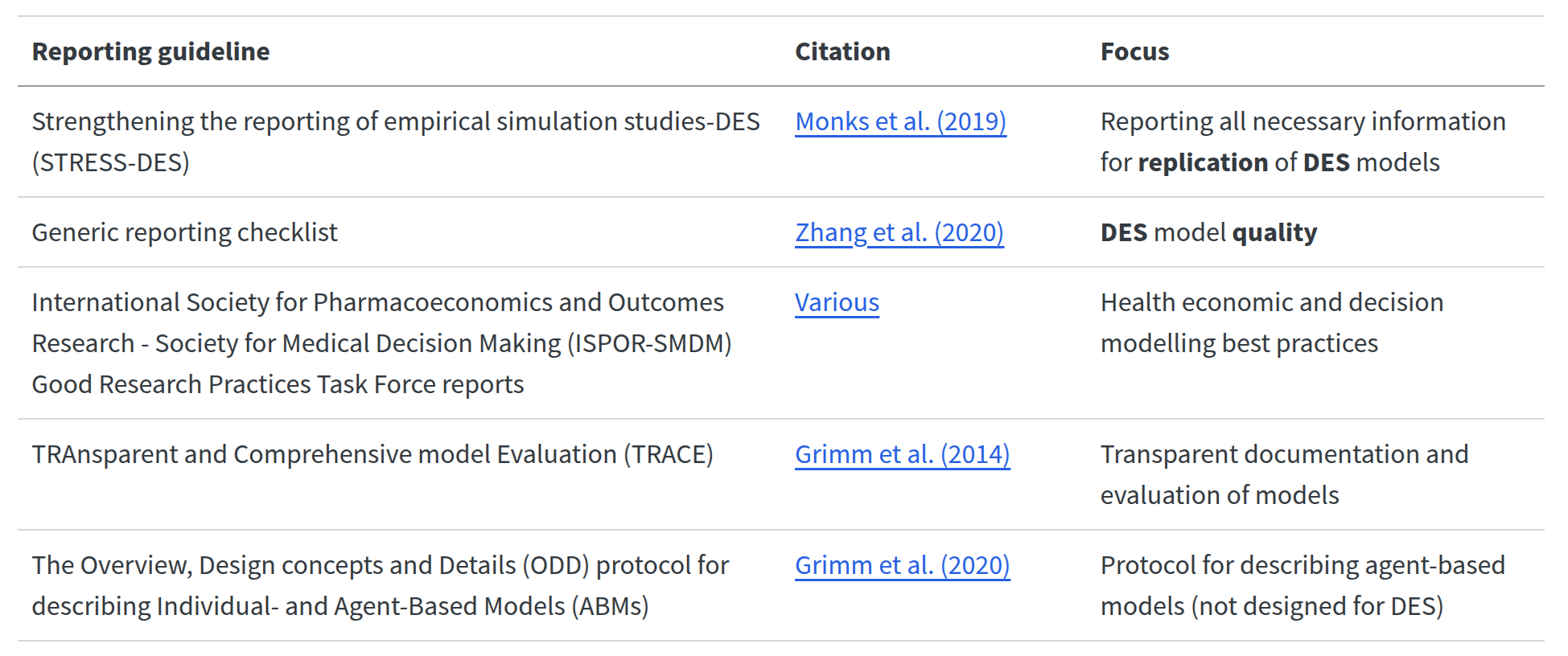
Sharing and archiving
Reporting guidelines: for documenting model.
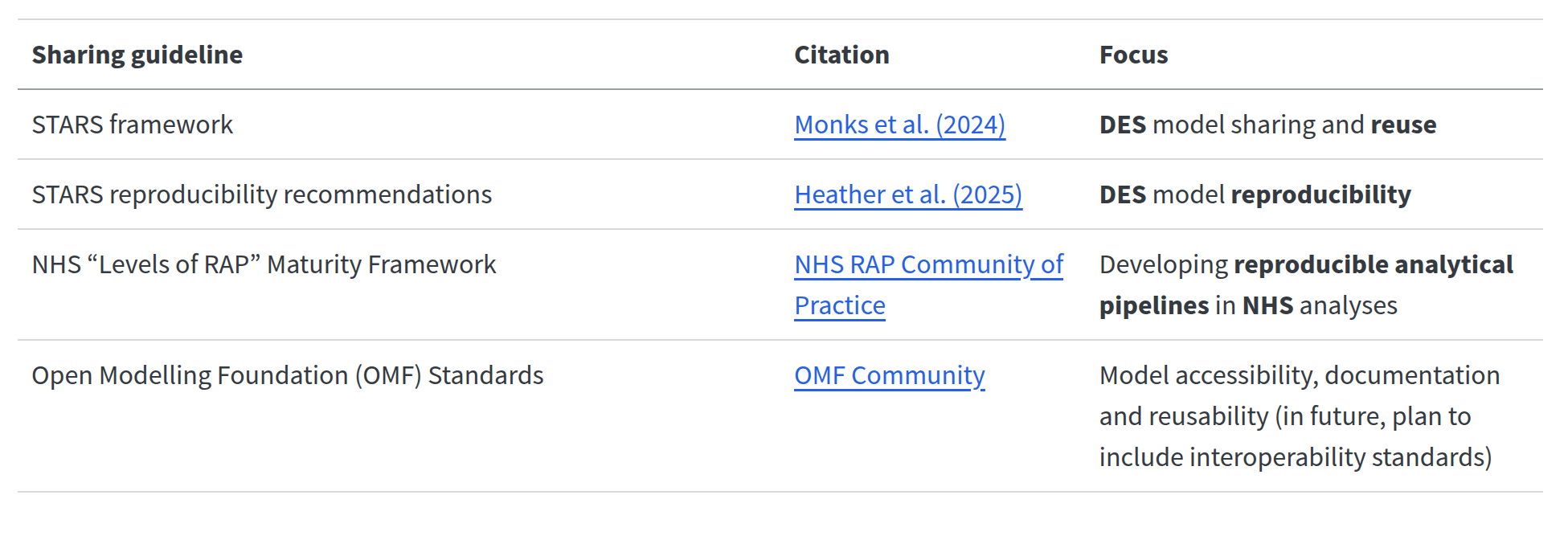
Sharing and archiving
Sharing guidelines: for code, data and materials.
Sharing and archiving
Archives provide long-term storage guarantees and create a DOI for your code.
Examples:
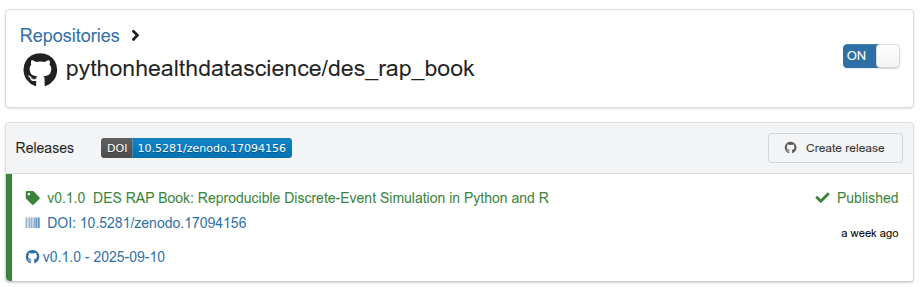
- Zenodo - triggered by GitHub release:
Acknowledgements
The DES RAP Book was written by Amy Heather and reviewed by Nav Mustafee, Alison Harper, Tom Monks, Fatemeh Alidoost, Rob Challen and Tom Slater.

STARS is supported by the Medical Research Council [grant number MR/Z503915/1] from 1st May 2024 to 31st October 2026.
This work was also supported by the National Institute for Health and Care Research (NIHR) under the NIHR Applied Research Collaboration South West Peninsula (Grant Reference Number NIHR200167). The views expressed are those of the author(s) and not necessarily those of the NIHR or the Department of Health and Social Care.
![]()
![]()
![]()

Check out: